![]()
Privaten Schlüssel (ohne Passphrase) erzeugen:
$ openssl genrsa -out private.pem 2048
Öffentlichen Schlüssel aus privatem Schlüssel erzeugen:
$ openssl rsa -in private.pem -pubout >public.pem
Nachricht mit öffentlichem Schlüssel verschlüsseln:
$ openssl pkeyutl -encrypt -pubin -inkey public.pem -in text.txt -out text.enc
Verschlüsselte Nachricht mit privatem Schlüssel entschlüsseln:
$ openssl pkeyutl -decrypt -inkey private.pem -in text.enc >text.dec

Wie in Einen Offline-Mirror des CPAN erstellen beschrieben, ist es möglich, eine beliebige Kollektion von CPAN-Modulen auf einem Rechner ohne Internet-Zugang zu installieren. Der Offline-Mirror hat aktuell eine Größe von ca. 5GB. Dies läßt sich reduzieren, indem man ihn auf genau die Module beschränkt, die man tatsächlich installieren möchte. Dies geht mit Bordmitteln wie folgt:
Einen Rechner mit Internet-Zugang wählen.
Auf diesem Rechner die benötigten Module in das (frei gewählte) MicroCPAN-Verzeichnis installieren:
$ cpanm --save-dists MICROCPANDIR --local-lib-contained MICRCPANDIR/inst --prompt MODULE ...
Das Verzeichnis um die CPAN Package-Liste ergänzen (diese umfasst alle CPAN-Module, auch wenn wir nur einen Teil davon nutzen):
$ curl -L http://www.perl.com/CPAN/modules/02packages.details.txt.gz --silent --output MICROCPANDIR/modules/02packages.details.txt.gz
Das MicroCPAN-Verzeichnis auf den Zielrechner (ohne Internet-Zugang) übertragen.
Die o.g. Module auf dem Zielrechner offline installieren:
$ cpanm --mirror MICROCPANDIR --mirror-only MODULE ...
Hierbei ist:
Das (frei gewählte) MicroCPAN-Verzeichnis auf dem Quell- und dem Zielrechner
Die Liste der Module, die auf dem Zielrechner offline installiert werden sollen
![]()
Wer in Deutschland einem öffentlichen Auftraggeber eine Rechnung stellen möchte, muss diese u.U. zwingend als XRechnung übermitteln. Was tun, wenn man hierfür keine Software besitzt?
Für gelegentliche Rechnungsstellung bietet sich hierfür das Portal https://xrechnung-bdr.de der Bundesdruckerei an. Dort kann man nach Registrierung die Rechnungsdaten in einem selbsterklärenden Arbeitsablauf eingeben. Nach Abschluss wird die XRechnung erzeugt und anhand der Leitweg-Id automatisch an den Empfänger übermittelt. Dies alles ist kostenfrei.
![]()
Eine Authentisierung über LDAP gegen ein Active Directory (AD) besteht im Kern im Aufruf der Methode bind(). Gelingt dieser Aufruf, ist der Benutzer authentisiert:
use Net::LDAP;
my $workgroup = '...';
my $user = '...';
my $password = '...';
my $ldap = Net::LDAP->new(
'ldaps://dc1', # verschlüsselte Verbindung
verify => 'none', # keine Verifikation des Server-Zertifikats (sollte eigetlich 'require' sein)
onerror => 'die', # Exception, wenn wenn nachfolgende Methodenaufrufe fehlschlagen
) or die $@;
$ldap->bind("$workgroup\\$user",password=>$password);
$ldap->unbind;
# ab hier ist der Benutzer authentisiert
In Dateien eines Verzeichnisbaums wollen wir eine mehrzeilige Ersetzung vornehmen. Unter Nutzung von Perl geht dies mit einem Einzeiler:
$ find DIR ... | xargs perl -0777 -p -i -E 's/REGEX/REPLACEMENT/gms'
Hierbei ist REGEX ein Regulärer Ausdruck, der Text über mehreren Zeilen matchen kann. Wie funktioniert der Aufruf?
Perl verarbeitet die Dateien, die von xargs(1) als Argumente übergeben werden, und behandelt sie gemäß den angegebenen Optionen:
Kein Input-Separator, d.h. Perl liest die jeweilige Datei komplett ein statt sie zeilenweise zu verarbeiten. Dadurch wirkt der Perl-Code, siehe Option -E CODE, nicht auf eine einzelne Zeile, sondern auf den gesamten Dateiinhalt.
Perl iteriert über die Dateien, die als Argumente angegeben sind, und gibt den Dateiinhalt jeweils nach Manipulation durch den Perl-Code CODE mit print aus.
Die Ausgabe mit print ersetzt den Inhalt der ursprünglichen Datei (Bearbeitung "in place"). Wird die Option -i mit einem Wert ergänzt, z.B. -i.orig, bleibt die Originaldatei mit der Endung .orig erhalten. Auf diesem Weg kann Code CODE gefahrlos getestet werden.
Der Perl-Code, der auf den Inhalt der Datei angewandt wird. Dieser kann beliebige Manipulationen vornehmen. Wir führen oben ein einzelnes Substitute s/// aus, mit den Optionen g (alle Fundstellen werden ersetzt), m (^ uns $ matchen Zeilenanfang und Zeilenende), s (der Punkt . matcht auch Zeilenumbrüche). Diese Semantik ist in dem gegebenen Anwendungsfall besonders nützlich.
Beispiel
Entferne im Verzeichnisbaum DIR die Inline-Dokumentation (POD) aus allen .pm-Dateien:
$ find DIR -name '*.pm' | xargs perl -0777 -p -i -E 's/^=[a-z].*?^=cut\n//gms'

SQLite ist ein leichtgewichtiges relationales Datenbanksystem, das genial konzipiert, allerdings nicht netzwerkfähig ist. Letzteres ist laut der Autoren Absicht: "SQLite is designed for situations where the data and application coexist on the same machine."
Mitunter möchte man dennoch eine SQLite-Datenbank von einem entfernten Rechner zugreifen. Dass es keine gute Idee ist, wie es im Netz öfter als Lösung genannt wird, die Datenbankdatei (eine SQLite-Datenbank besteht aus einer einzigen Datei) auf ein Netzwerk-Dateisystem zu legen, wird von den Autoren in SQLite Over a Network, Caveats and Considerations dargelegt.
Unter Perl lässt sich der Netzwerk-Zugriff auch solide unter Rückgriff auf DBI und dessen Proxy-Server realisieren. Der Unterschied ist, dass in dem Fall die API Schicht ins Netz verlegt wird und nicht die File-I/O Schicht (s. obiges Dokument).
Starten des Proxy-Servers auf dem Rechner mit der SQLite-Datenbank:
$ ssh USER@HOST "bash -lc 'dbiproxy --localport=PORT'"
Zugriff auf die Datenbank aus Perl heraus von einem beliebigen Rechner aus:
use DBD::SQLite;
my $dbh = DBI->connect('dbi:Proxy:hostname=HOST;port=PORT;dsn=DSN',{
RaiseError => 1,
ShowErrorStatement => 1,
});
# ab hier können wir auf die SQLite-Datenbank zugreifen, als ob sie lokal wäre
Hierbei ist:
Der Name des Rechners, auf dem die SQLite-Datenbank liegt.
Der Port, auf dem der Proxy-Server läuft.
Der DBI Data Source Name der SQLite-Datenbank. Dieser hat die Form dbi:SQLite:dbname=PATH, wobei PATH der Pfad der Datenbank-Datei auf dem entfernten Rechner ist.
Eine breitere Darstellung der Möglichkeiten des DBI Proxy-Servers findet sich in Programming the Perl DBI - Database Proxying.
Warnung: Der DBI Proxy-Server hat offenbar ein Memory Leak und sollte daher nicht unbegrenzt lange laufen.
Soll lediglich mit dem SQLite-Client auf eine entfernte Datenbank zugegriffen werden, kann dies per ssh(1) erreicht werden:
$ ssh -t USER@HOST sqlite3 PATH
![]()
Zahlreiche ältere Bücher von O'Reilly, die nur noch antiquarisch erhältlich sind, können hier online gelesen werden. Vieles ist veraltet, manche Themen sind jedoch nach wie vor relevant und hervorragend dargestellt. Die umfangreiche Sammlung lädt zum Stöbern ein:

Beispiele:
![]()
Die Mausunterstützug wird im Emacs-Init-File (~/.emacs.el, ~/.emacs oder ~/.emacs.d/init.el) aktiviert mit:
(xterm-mouse-mode 1)
Auch das Mausrad wird unterstützt. Eine Markierung wird in den Paste-Buffer (Copy & Paste) kopiert, wenn gleichzeitig die SHIFT-Taste gehalten wird. Aus dem Paste-Buffer wird per Default mit SHIFT MOUSE-RIGHT eingefügt. Wer lieber mit der mittleren Maustaste (MOUSE-MIDDLE) einfügen möchte, wie man es von X11 her kennt, kann diese Bedienlogik unter Window / Selection / Action of mouse buttons / xterm aktivieren.
Funktioniert im Emacs die Cursorsteuerung über das Numeric Keypad nicht (das Verhalten ist wie im NumLock-Modus, d.h. anstatt Cursorbewegungungen auszuführen zeigt der Emacs Ziffern an), muss der "Application Keypad mode" in PuTTY abgeschaltet werden. Zu finden ist die Option in den Einstellungen unter Terminal / Features / Disable application keypad mode. Die Cursorsteuerung funktioniert natürlich nur, wenn der NumLock-Modus auf dem Keyboard tatsächlich abgeschaltet ist.
![]()
Wir rufen PuTTYgen auf und erzeugen ohne Änderung an den Voreinstellungen durch Betätigung des Buttons Generate ein RSA Schlüsselpaar mit 2048 Bit Schlüssellänge:
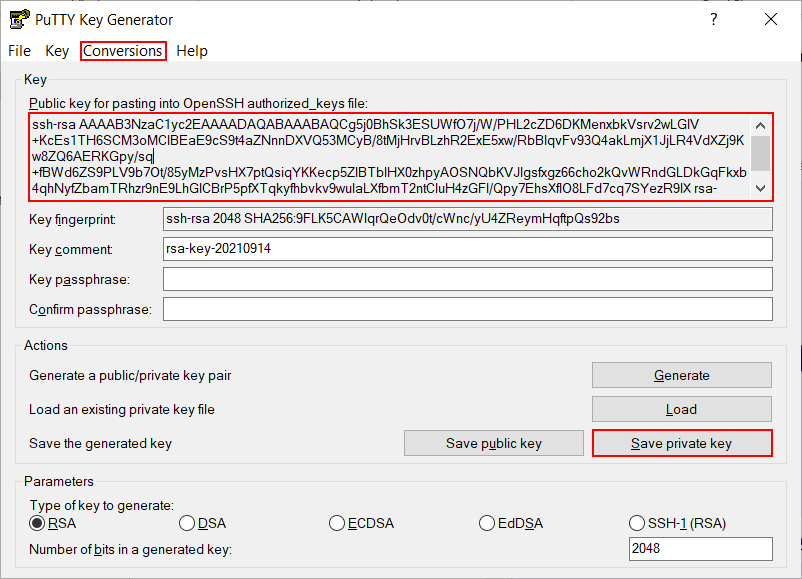
Anschließend speichern wir drei Dateien, um in einem Netzwerk aus Windows-Clients und Linux-Servern eine Anmeldung mit Public-Key-Authentisierung einrichten zu können:
Mit Copy & Paste speichern wir den Public Key, der im oberen Bereich des Fensters angezeigt wird, in id_rsa.pub. Den Inhalt dieser Datei fügen wir auf allen Linux-Servern, auf denen wir uns mit Public-Key-Authentisierung einloggen wollen, zur Datei .ssh/authorized_keys hinzu.
Mit Klick auf Save private key speichern wir den Private Key in id_rsa.ppk. Diese Datei machen wir allen Windows-Clientprogrammen bekannt, mit denen wir uns per Public-Key-Authentisierung auf einem Linux-Server einloggen wollen. Im PuTTY-Client z.B. wird der Dateipfad in die Konfiguration eingetragen unter Connection / SSH / Auth / Private key file for authentication.
Verlangt ein Client die PPK-Datei in einem älteren Format (Version 2 statt Version 3), können wir dieses erzeugen, indem wir unter Key / Parameters for saving files ... die Option PPK file version: 2 setzen, bevor wir den Private Key speichern.
Wollen wir uns ferner zwischen Linux-Rechnern per Public-Key-Verfahren authentisieren, erzeugen wir über den Menüeintrag Conversions / Export OpenSSH key den Private Key für Linux und speichern diesen in rsa_id. Diese Datei hinterlegen wir auf den Linux Rechern, von denen aus wir uns auf andere Linux-Rechner per Public-Key-Authentisierung einloggen wollen, in .ssh/rsa_id. Die Datei darf nur für ihren Owner lesbar sein und muss daher mit chmod 600 .ssh/rsa_id gegen fremden Zugriff geschützt werden.
![]()
Wir entwickeln auf Basis von Mojolicious eine Webanwendung NAME und möchten, dass diese
Diese Anforderungen lassen sich leicht mit morbo als Webserver in Kombination mit der Prozesssteuerung systemd realisieren. Hierbei ist morbo der Entwicklungs-Webserver von Mojolicious und systemd die fundamentale Prozesssteuerung vieler Linux-Systeme (ein moderner Ersatz für init). Ein zusätzlicher Webserver wie nginx oder apache wird nicht benötigt.
Die Unit-Datei NAME.service, mit der wir den Service gegenüber systemd definieren, ist recht einfach (Erläuterungen zur einzig interessanten Zeile ExecStart siehe im Folgenden):
[Unit]
Description=DESCRIPTION
After=network.target
[Service]
Type=simple
User=USER
ExecStart=bash -lc "morbo PROGRAM --listen http://*:PORT --watch SOURCEDIR --verbose >LOGFILE.log 2>&1"
[Install]
WantedBy=multi-user.target
Hierbei ist:
Eine kurze, einzeilige Beschreibung des Service.
Der Name des Unix-Users, unter dessen Rechten der Prozess ausgeführt wird, denn wir möchten, dass der Prozess im Kontext eines bestimmten Users läuft. Wenn nicht angegeben, ist root der User.
Pfad/Name des Programms, das die Webanwendung ausführt. Wir rufen die Anwendung nicht direkt auf, sondern via bash -lc "...", damit sie in der Umgebung des Users USER läuft.
Port, auf dem die Anwendung läuft. Wegen * ist sie auf allen Interfaces erreichbar, d.h. sie ist zugreifbar via localhost:PORT oder HOSTNAME:PORT.
Wurzelverzeichnis, im dem sich die Quellen der Anwendung befinden. Dieses Verzeichnis überwacht morbo in Bezug auf Änderungen. Verteilen sich die Quellen über mehrere Verzeichnisse, kann die Option --watch mehrfach angegeben werden.
Pfad/Name der Logdatei, in die der Webserver (morbo) die Zugriffe und Fehlermeldungen protokolliert. Die Logdatei wird beim Booten neu begonnen, womit auf einfache Weise vermieden wird, dass sie unbegrenzt wächst, historische Information wird in der Entwicklungsumgebung ja nicht benötigt.
Die systemd Unit-Datei kopieren wir in das Verzeichnis /etc/systemd/system. Mit folgender Kommandofolge machen wir die Anwendung dauerhaft und sofort verfügbar:
# systemctl daemon-reload # Konfigurationsänderung systemd bekannt machen # systemctl enable NAME # Service aktivieren, so dass die Anwendung beim Booten gestartet wird # systemctl start NAME # Service sofort verfügbar machen (ohne Rebooten zu müssen)
Den Status überprüfen wir mit:
# systemctl status NAME
Die Anwendung kann jederzeit gestoppt und gestartet werden mit:
# systemctl stop NAME # systemctl start NAME
Der automatische Start beim Booten lässt sich ab- und anschalten mit:
# systemctl disable NAME # systemctl enable NAME
Die Liste aller vorhandenen Unit-Files und ihres jeweiligen Status:
# systemctl list-unit-files
Vorschlag für eine Verzeichnisstruktur im Homeverzeichnis von USER:
~/etc/systemd/NAME.service # Unit-Datei, per Symlink referenziert von /etc/systemd/system aus, Qwner ist USER ~/var/log/NAME.log # Logdatei ~/opt/NAME/... # Projektverzeichnis
Die konkrete Kommandozeile zum Starten der Anwendung lautet dann:
morbo ~/opt/NAME/bin/PROGRAM --listen http://*:PORT --watch ~/opt/NAME --verbose >~/var/log/NAME.log 2>&1
nohup morbo ~/opt/NAME/bin/PROGRAM --listen http://*:PORT --watch ~/opt/NAME --verbose >~/var/log/NAME.log 2>&1 &

Unter Linux (Debian) bricht eine zuvor funktionierende Oracle-Datenbank beim Hochfahren plötzlich ab. Die Meldung lautet:
ORA-00845: MEMORY_TARGET not supported on this system
Im Netz wird in Blogs als Lösung genannt, man möge /dev/shm mounten
# mount -t tmpfs tmpfs -o size=2g /dev/shm
oder, falls /dev/shm bereits gemountet ist, den Speicher vergrößern
# mount -o remount,size=2g /dev/shm
Dies hat beides allerdings nicht geholfen, da es eine weitere Fehlerursache gibt. Die Meldung im alert_<DB>.log zu dem Fehler lautet:
WARNING: You are trying to use the MEMORY_TARGET feature. This feature requires the /dev/shm file system to be mounted for at least 1275068416 bytes. /dev/shm is either not mounted or is mounted with available space less than this size. Please fix this so that MEMORY_TARGET can work as expected. Current available is 0 and used is 0 bytes. Ensure that the mount point is /dev/shm for this directory.
Der entscheidende Punkt in der Meldung, welcher zur Lösung führt, ist, dass Oracle keinen verfügbaren Speicher erkennt ("Current available is 0 and used is 0 bytes") und dass der Mountpoint exakt /dev/shm sein muss ("Ensure that the mount point is /dev/shm for this directory").
Letztere Bedingung war auf dem Debian-System (testing) nicht erfüllt:
# df -h /dev/shm Filesystem Size Used Avail Use% Mounted on tmpfs 3.0G 0 3.0G 0% /run/shm
Als Mountpoint wird hier nicht /dev/shm angezeigt, sondern /run/shm, weil /dev/shm lediglich ein Symlink auf /run/shm ist:
# ls -l /dev/shm lrwxrwxrwx 1 root root 8 Aug 7 09:37 /dev/shm -> /run/shm
Mit diesem Setup kommt der Oracle-Kernel (11.2.0.1.0) nicht klar. Er erkennt (aus nicht weiter erforschten Gründen) die Größe des Shared-Memory-Bereichs nicht.
Der Fix besteht darin, im Oracle-Kernel alle Vorkommen von /dev/shm durch /run/shm zu ersetzen:
# cd $ORACLE_HOME/bin # cp oracle oracle.bak # sed 's|/dev/shm|/run/shm|g' oracle.bak >oracle
Danach fährt die Datenbank wieder hoch:
$ sqlplus / as sysdba SQL*Plus: Release 11.2.0.1.0 Production on Fri Aug 7 13:29:21 2020 Copyright (c) 1982, 2009, Oracle. All rights reserved. Connected to an idle instance. SQL> startup ORACLE instance started. Total System Global Area 1272213504 bytes Fixed Size 1336260 bytes Variable Size 805309500 bytes Database Buffers 452984832 bytes Redo Buffers 12582912 bytes Database mounted. Database opened.
![]()
Wer im Netz nach "debian installation" sucht, stößt auf folgendes Dokument: Debian GNU/Linux Installation Guide, welches erschlagend ist. Dabei ist die Installation von Debian sensationell einfach:
ISO-Image von Homepage herunterladen: https://www.debian.org/ (Button "Download")
Image auf ungemounteten USB-Stick kopieren (cp FILE.iso /dev/sdX)
Rechner vom USB-Stick booten
Installation durchführen
Voraussetzung hierfür ist, dass der Rechner, auf dem die Installation stattfindet, eine Verbindung ins Internet aufbauen kann (per Ethernet oder WLAN). Zusätzlicher Vorteil: Der Stick kann auch im Recovery-Fall genutzt werden (eine Netzwerkverbindung ist in dem Fall nicht nötig).
![]()
PyPerler ist ein Python-Package mit dem es möglich ist, Perl-Code unter Python zu nutzen. Es wird vom Autor nach eigener Aussage zur Zeit nicht gepflegt, funktioniert aber recht gut (Einschränkungen siehe unten). Es lassen sich damit sogar komplexe Perl-Klassen unter Python verwenden, wie z.B. Datenbank-Operationen über einen O/R-Mapper. Ich experimentiere zur Zeit damit unter Debian 10 mit Python 3.7.3 und Perl 5.28.1.
Wir setzen zunächt eine virtuelle Umgebung auf, in die wir PyPerler installieren:
$ virtualenv venv $ . venv/bin/activate
Wir holen den Sourcecode von GitHub:
$ git clone https://github.com/tkluck/pyperler.git
Wir kompilieren den Code und installieren PyPerler in die virtuelle Umgebung:
$ cd pyperler $ make $ make install
Nun können wir Perl-Code von Python aus nutzen. Ein Beispiel findet sich im README.
Die Operator-Methoden __radd__(), __rmul__() usw. fehlen in Klasse ScalarValue, so dass unter o.g. Python-Version ein Perl-Skalar ohne explizite Typwandlung zwar linksseitig mit einem Python-Objekt verknüpft werden kann, aber nicht rechtsseitig. Diese Definitionen lassen sich relativ einfach nachtragen. Als Richtschnur kann
$ make check
genutzt werden, das die Defizite aufzeigt.
Pyperler ist offenbar nicht thread-save. Eine Flask-Anwendung muss mit
$ flask run --without-threads
gestartet werden, sonst stürzt sie mit einem Segmentation Fault beim ersten Zugriff auf ein Perl-Objekt ab. Dies hat möglicherweise mit einem Fehler bei der Nutzung von Cythons Global Interpreter Lock (GIL) zu tun.
![]()
Aus Sicherheitsgründen lassen moderne Browser Ajax-Requests über Domaingrenzen hinweg nur dann zu, wenn die angefragte Resource die anfragende Domain "kennt". Ob dies der Fall ist, teilt die Resource dem Browser über den HTTP-Header Access-Control-Allow-Origin mit:
Access-Control-Allow-Origin: <origin>
Liefert die angefragte Resource diesen Header nicht oder passt <origin> nicht zur anfragenden Seite, verwirft der Browser die Response. Firefox z.B. schreibt dann die Warnung ins Console Log
Cross-Origin Request Blocked: The Same Origin Policy disallows reading the remote resource at ...
mit dem Zusatz
(Reason: CORS header 'Access-Control-Allow-Origin' missing)
wenn der Header fehlt, oder
(Reason: CORS header 'Access-Control-Allow-Origin' does not match '...')
wenn <origin> nicht passt.
Möchte die angefragte Resource Zugriffe von jeglichen Domains zulassen, liefert sie einfach
Access-Control-Allow-Origin: *
Möchte sie den Zugriff von mehreren (aber nicht allen) Domains zulassen, muss sie <origin> dynamisch zur jeweils anfragenden Seite setzen, die ihre Origin unter dem Header Origin: sendet.
![]()
Die folgenden Diagramme zeigen Zeitreihen-Plots (am Beispiel von Umweltdaten) mit "Rangeslider" auf Basis des JavaScript Plot-Frameworks Plotly.js. Die Zeitreihen behandele ich als eine Einheit, wobei ich folgende Bedienlogik realisiert habe:
In dem Diagramm, dessen Rangeslider aktiviert ist (siehe Checkbox am jeweiligen Diagramm), kann mit der linken Maustaste im Plot ein Zeitbereich ausgewählt und anschließend mit dem Rangeslider durch den Gesamtbereich gescrollt werden. Das Zoomen und Scrollen findet dabei über allen Diagrammen synchron statt. Bei Doppelklick in den Plot-Breich wird der ursprüngliche Zustand über allen Diagrammen wieder hergestellt.
Mit dem Button "Scale Y Axis" kann die Y-Achse auf den Wertebereich der sichtbaren Daten skaliert werden. Dies ist nützlich, wenn in einen Zeitbereich mit geringen Wertänderungen hineingezoomt wurde. Bei einer zweiten Betätigung wird der ursprünglche Zustand der Y-Skalierung wieder hergestellt. Bei Doppelklick in irgendein Diagramm werden alle Y-Achsen gemeinsam wieder hergestellt.
Beim Überfahren der Plots mit der Maus wird das Koordinatenpaar des nächstgelegenen Punktes angezeigt.
Im Menü "Shape" kann die Kurvendarstellung eingestellt werden. Spline: Die Messwerte werden durch eine Spline-Approximation verbunden. Linear: Die Messwerte werden durch eine gerade Linie verbunden. Marker: Die Messwerte werden nicht verbunden, sondern durch einen Punkt dargestellt. Quality: Wie Marker, nur dass in der Farbe des Punktes eine dritte Dimension (hier: die Qualität des Messwerts) kodiert ist.
Mittels des Buttons "Download as PNG" kann das Diagramm als Grafik heruntergeladen werden. Soll er Rangeslider darauf nicht erscheinen, bietet es sich an, diesen vorher wegzuschalten.
Die geplotteten Daten sind nicht Teil der HTML-Seite (!), sondern werden per Ajax-Request von einer anderen Site via Cross-Origin Resource Sharing asynchron geladen.
Sonderfall "Keine Daten": Das letzte Diagramm (GlobalRadiation) zeigt die Darstellung, wenn im gegebenen Zeitbereich keine Daten vorliegen.
| Rangeslider: | Shape: | FillArea: | | |
| Rangeslider: | Shape: | FillArea: | | |
| Rangeslider: | Shape: | FillArea: | | |
| Rangeslider: | Shape: | FillArea: | | |
| Rangeslider: | Shape: | FillArea: | | |

Ausgangslage:
In einer Datenbank mydb1 befindet sich eine Tabelle myschema1.mytable
In einer zweiten Datenbank mydb2 befindet sich eine View myschema2.myview
View myschema2.myview selektiert Tabelle myschema1.mytable
Anforderung:
Es soll ein Server-Zugang mylogin geschaffen werden, der Daten über View myschema2.myview selektieren darf, aber nicht direkt aus Tabelle myschema1.mytable.
Lösung:
Login mylogin erzeugen mit dem User-Mapping: mydb1 -> myuser1 und mydb2 -> myuser2.
User myuser1 erhält keine speziellen Rechte.
User myuser2 erhält Leserecht auf View myschema2.myview.
Den Schemata myschema1 und myschema2 den gleichen Owner geben (und damit den enthaltenen Objekten mytable und myview).
Für die Datenbanken mydb1 und mydb2 "cross-database ownership chaining" aktivieren.
SQL:
CREATE LOGIN mylogin WITH PASSWORD = 'mypassword';
CREATE DATABASE mydb1;
ALTER DATABASE mydb1 SET DB_CHAINING ON;
CREATE DATABASE mydb2;
ALTER DATABASE mydb2 SET DB_CHAINING ON;
USE mydb1;
CREATE SCHEMA myschema1;
CREATE TABLE myschema1.mytable (id INT PRIMARY KEY);
CREATE USER myuser1 FOR LOGIN mylogin;
USE mydb2;
CREATE SCHEMA myschema2;
CREATE USER myuser2 FOR LOGIN mylogin;
CREATE VIEW myschema2.myview AS SELECT * FROM mydb1.myschema1.mytable;
GRANT SELECT ON myschema2.myview TO myuser2;
Über mylogin ausgeführt:
-- erfolgreich
SELECT * FROM mydb2.myschema2.myview;
-- schlägt fehl: The SELECT permission was denied on the object 'mytable',
-- database 'mydb1', schema 'myschema1'
SELECT * FROM mydb1.myschema1.mytable;
![]()
Das potentiell komplexeste Statement in SQL ist das SELECT-Statement. Dieses wiederverwendbar zu kapseln, z.B. in einer Methode einer Klasse, kann eine Herausforderung sein. Dieses Problem wollen wir hier allgemeingültig lösen.
Hier ein Beispiel. Mit folgendem SELECT-Statement wollen wir aus dem Data Dictionary (Catalog) von PostgreSQL Informationen über die auf der Datenbank definierten Datenbank-Funktionen abfragen:
SELECT
fnc.oid AS fnc_oid
, usr.usename AS fnc_owner
, nsp.nspname AS fnc_schema
, fnc.proname AS fnc_name
, pg_get_function_identity_arguments(pro.oid) AS fnc_arguments
, pg_get_functiondef(fnc.oid) AS fnc_source
FROM
pg_proc AS fnc
JOIN pg_namespace AS nsp
ON fnc.pronamespace = nsp.oid
JOIN pg_user usr
ON fnc.proowner = usr.usesysid
Dieses relativ kurze Statement besitzt eine beachtliche Komplexität. Es erstreckt sich über drei Relationen (zwei Tabellen, eine View), deren Aufbau und Verknüpfung alles andere als offensichtlich ist. Wir wollen es so kapseln, dass wir bei Abfragen keine Details über die interne Repräsentation des Data Dictionary wissen müssen. In einem ersten Schritt haben wir den Kolumnen bereits Aliasnamen gegeben (s.o.), aus denen sich die Bedeutung der Kolumnen recht klar ergibt:
Statt oid. Objekt-Id der Funktion.
Statt usename. Name des Owners der Funktion.
Statt nspname. Name des Schemas, in dem sich die Funktion befindet.
Statt proname. Name der Funktion.
Statt pg_get_function_identity_arguments(oid). Argumentliste der Funktion als kommaseparierte Aufzählung der Datentypen. Diese Information ist bedeutsam, da eine Funktion nur durch ihre Signatur (Name plus Argumentliste) eindeutig bestimmt ist.
Statt pg_get_functiondef(oid). Quelltext der Funktion.
Über diesen Kolumnen wollen wir unsere Abfragen formulieren. Das Problem ist jedoch, dass wir die Kolumnen-Aliase nicht überall in einer Abfrage verwenden können, auch nicht in der WHERE-Klausel, die die Ergebnismenge bestimmt. Wenn wir obiges Statement um eine WHERE-Klausel ergänzen, müssen wir dort also weiterhin die internen Namen verwenden. Das wollen wir gerade nicht.
Eine mögliche Lösung ist das Anlegen einer View:
CREATE VIEW function_view AS
<obiges_statement>
Durch die View werden die internen Namen verdeckt. Abfragen der View werden allein über den Kolumnennamen des zugrundeliegenden Statements formuliert. Das ist genau das, was wir wollen. Mit der View schaffen wir allerdings eine öffentliche Schnittstelle, die wir (ohne besondere Vorkehrungen) nicht nach Belieben anlegen (Namenskonflikte) und ändern können (wir wissen nicht, wer die View sonst noch nutzt). Dies ist das Gegenteil einer Kapselung. Das Ziel einer echten Kapselung in einer Methode, und nur dort, erreichen wir mit einer View nicht.
Eine in dieser Hinsicht bessere Lösung bietet eine Inline-View, die nur innerhalb unserer Methode bekannt ist. Bei einer Inline-View betten wir das Select-Statement in die FROM-Klausel unserer Abfrage ein:
SELECT
...
FROM (
<obiges_statement>
) AS function_view
...
Diese Lösung hat jedoch den Nachteil, dass sie nicht portabel ist. Z.B. erzwingt PostgreSQL einen Namen für die Inline-View (AS function_view), Oracle jedoch nicht. Wobei ein Name im Falle von Oracle zwar vereinbart werden kann, dann aber ohne das Schlüsselwort AS.
Eine weitere Möglichkeit bietet die Einbettung in eine WITH-Klausel:
WITH function_view AS (
<obiges_statement>
)
SELECT
...
FROM
function_view
...
Diese Lösung ist portabel und separiert die konkrete Abfrage (SELECT ... FROM function_view ...) klar von dem gekapselten SELECT-Statement.
Auf dieser Grundlage können wir die Selektion wie gewünscht kapseln. Hier die Implementierung einer Methode in Perl, die so ausgelegt ist, dass die Klauseln SELECT (Namensparameter select), WHERE (Namensparameter where) und ORDER BY (Namensparameter orderBy) frei gesetzt werden können:
package PostgreSql::Catalog;
sub functionSelect {
my ($class,%clause) = @_;
# Defaults
$clause{'select'} //= ['*']; # Default für SELECT-Klausel
$clause{'from'} = ['function_view']; # FROM-Klausel ist festgelegt
# Gekapselter Statement-Rumpf
my $stmt = << ' __SQL__';
WITH function_view AS (
SELECT
fnc.oid AS fnc_oid
, usr.usename AS fnc_owner
, nsp.nspname AS fnc_schema
, fnc.proname AS fnc_name
, pg_get_function_identity_arguments(pro.oid) AS fnc_arguments
, pg_get_functiondef(fnc.oid) AS fnc_source
FROM
pg_proc AS fnc
JOIN pg_namespace AS nsp
ON fnc.pronamespace = nsp.oid
JOIN pg_user usr
ON fnc.proowner = usr.usesysid
)
__SQL__
$stmt =~ s/^ //mg;
# Erzeuge vollständiges Statement über den angegebenen Klauseln
for my $key (qw/select from where orderBy/) {
if (my $arr = $clause{$key}) {
my $clause = $key eq 'orderBy'? 'ORDER BY': uc $key;
$stmt .= sprintf "%s\n %s\n",$clause,join "\n , ",@$arr;
}
}
return $stmt;
}
Beispiel: Der Aufruf
# Ermittele alle Funktionen im Schema 'donald', deren Quelltext
# die Zeichenkette 'to_date' enthält
$sql = PostgreSql::Catalog->functionSelect(
select => [
"fnc_schema",
"fnc_name || '(' || fnc_arguments || ')' AS fnc_signature",
],
where => [
"fnc_schema = 'donald'",
"fnc_source LIKE '%to_date%'",
],
orderBy => [
1,
2
],
);
generiert das Statement
WITH function_view AS (
SELECT
fnc.oid AS fnc_oid
, usr.usename AS fnc_owner
, nsp.nspname AS fnc_schema
, fnc.proname AS fnc_name
, pg_get_function_identity_arguments(pro.oid) AS fnc_arguments
, pg_get_functiondef(fnc.oid) AS fnc_source
FROM
pg_proc AS fnc
JOIN pg_namespace AS nsp
ON fnc.pronamespace = nsp.oid
JOIN pg_user usr
ON fnc.proowner = usr.usesysid
)
SELECT
fnc_schema
, fnc_name || '(' || fnc_arguments || ')' AS fnc_signature
FROM
function_view
WHERE
fnc_schema = 'donald'
AND fnc_source LIKE '%to_date%'
ORDER BY
1
, 2
das wir gegen die Datenbank ausführen können.
Wir haben folgendes erreicht:
Wir haben das Gerüst eines komplexen Select-Statements in einer Methode gekapselt.
Wir haben eigene Kolumnennamen vereinbart, über denen wir Selektionen formulieren können. Nur diese Namen muss der Aufrufer kennen.
Wir haben eine Methode geschaffen, die eine Schnittstelle zur Erzeugung von frei formulierten Selektionen über dem gekapselten Statement bereitstellt.
![]()
Koordinaten eines (Raster-)Bildes der Breite width und der Höhe height:
![]()
Der Ursprung (0, 0) des Bild-Koordinatensystems ist oben links. Eine Bild-Koordinate bezeichnen wir mit (posX, posY), wobei posX und posY ganzzahlig sind.
Bei der Erzeugung eines XY-Plot bilden wir zwei beliebige numerische Wertebereiche minX .. maxX (X-Wertebereich) und minY .. maxY (Y-Wertebereich) auf das Bild-Koordinatensystem ab. Dem XY-Plot liegt dabei ein kartesisches Koordinatensystem zugrunde, dessen Ursprung (minX, minY) unten links ist.
Bild-Koordinate posX zu einem Wert x aus dem X-Wertebereich minX .. maxX:
![]()
Bild-Koordinate posY zu einem Wert y aus dem Y-Wertebereich minY .. maxY:
![]()
![]()
Das Python-Programm
#!/usr/bin/env python3
from selenium import webdriver
driver = webdriver.Firefox()
# eof
führt unter Debian zu dem Fehler
Traceback (most recent call last):
File "./test.py", line 5, in <module>
driver = webdriver.Firefox()
File ".../venv/lib/python3.7/site-packages/selenium/webdriver/firefox/
webdriver.py", line 174, in __init__ keep_alive=True)
File ".../venv/lib/python3.7/site-packages/selenium/webdriver/remote/
webdriver.py", line 157, in __init__ self.start_session(capabilities,
browser_profile)
File ".../venv/lib/python3.7/site-packages/selenium/webdriver/remote/
webdriver.py", line 252, in start_session response = self.execute(
Command.NEW_SESSION, parameters)
File ".../venv/lib/python3.7/site-packages/selenium/webdriver/remote/
webdriver.py", line 321, in execute self.error_handler.check_response(
response)
File ".../venv/lib/python3.7/site-packages/selenium/webdriver/remote/
errorhandler.py", line 242, in check_response raise exception_class(
message, screen, stacktrace)
selenium.common.exceptions.SessionNotCreatedException: Message: Unable
to find a matching set of capabilities
Grund hierfür ist, dass unter Debian firefox ein Shellskript ist, das das "richtige" Firefox-Executable firefox-esr indirekt aufruft. Damit kann der WebDriver von Firefox (geckodriver) nicht umgehen. Die Lösung ist, bei der Instantiierung des Firefox-Drivers den Pfad zum Firefox-Executable explizit anzugeben:
#!/usr/bin/env python3
from selenium import webdriver
driver = webdriver.Firefox(firefox_binary="/usr/bin/firefox-esr")
# eof
$ virtualenv venv $ . venv/bin/activate $ pip install selenium $ curl -L https://github.com/mozilla/geckodriver/releases/download/v0.27.0/ geckodriver-v0.27.0-linux64.tar.gz | (cd venv/bin; tar xvzf -)
(mit dem geckodriver, der zum Zeitpunkt dieses Artikels aktuell war)
![]()
Ein sehr nützliches Konzept in Emacs sind Rectangles (Rechtecke). Es gibt diverse Kommandos, um auf ihnen zu operieren. Mit C-SPC wird zunächst eine Marke auf die eine Ecke des Rechtecks gesetzt, dann wird mit dem Cursor zur gegenüberliegenden Ecke navigiert. Anschließend kann ein Kommando auf das Rechteck angewendet werden. Die Rectangle-Kommandos beginnen mit C-x r. Referenz: Rectangle Commands
Ersetze jede Zeile des Rechtecks durch eine Zeichenkette (dies kann zum Auskommentieren genutzt werden):
C-x r t <string> RET
Umkehrung. Entferne ein markiertes Rechteck (kann zum wieder Einkommentieren genutzt werden):
C-x r d
![]()
In GIMP wird beim Exportieren eines Bildes der Dateiname generell mit der Endung .png vorbelegt. Wenn man Bilder meist als JPEG (Endung .jpg) speichert, ist es lästig, ständig die Endung in .jpg ändern zu müssen. GIMP scheint keine Einstellung für ein Default Exportformat zu kennen. Hier ein Weg, wie man bei einem GIMP Executable trotzdem JPEG als Default-Exportformat festlegen kann: How to set Gimp default export to JPEG. Ich habe es ausprobiert (GIMP 2.10.8), es funktioniert.
Zusammenfassung:
$ which gimp
/usr/bin/gimp
$ ghex /usr/bin/gimp # "extension.png" durch "extension.jpg" ersetzen
In ghex Edit/Replace auswählen, dann auf der rechten Seite Such- und Ersetzung-String eintragen und per Button Replace Ersetzung durchführen.
![]()
$ cd DIR $ git init $ git add . $ git commit -m "Erstes Commit"
(Dieser Schritt kann natürlich übersprungen werden, wenn das Verzeichnis bereits unter der Kontrolle von Git steht.)
Auf GitHub einloggen und ein leeres Repository unter dem Menüpunkt + | New Repository erstellen. GitHub empfiehlt, in diesem Schritt keine README-, license- oder .gitignore-Datei generieren zu lassen, um Konflikte mit eventuell schon existierenden lokalen Dateien auszuschließen.
$ git remote add origin URL $ git push -u origin master
Hierbei ist URL die Adresse des GitHub-Repository, die nach dessen Anlegen in Schritt 2. im oberen Teil der Seite angezeigt wird,
git@github.com:USER/REPO.git # SSH-Protokoll
oder
https://github.com/USER/REPO.git # HTTPS-Protokoll
Besser ist es, SSH als Protokoll zu nutzen, da dann Public Key Athentifizierung ohne Passworteingabe genutzt werden kann.
Wurde unter 3. HTTPS als Protokoll gewählt, kann dies nachträglich geändert werden mit:
$ git remote set-url origin git@github.com:USER/REPO.git
![]()
![]()
Mein Pixel C Tablet ließ sich plötzlich (d.h. ohne ersichtlichen Grund) nicht mehr entsperren. Der Zugang lässt sich dann nur durch Zurücksetzen des Systems in den Werkszustand wiederherstellen. Dies erwies sich als unerwartet verwickelt. Hier der Ablauf:
System neu starten, dabei die Tasten "Power" und "Leiser" gedrückt halten.
Es erscheint ein Boot-Menü. Mit "Leiser/Lauter" den Menüpunkt Reboot into Android Recovery auswählen. Auswahl mit "Power" bestätigen.
Das System wird neu gestartet. Es erscheint ein umgekippter Android (s.u.) mit der Meldung "No command".
Was aussieht wie ein fataler Fehler, ist keiner. Die Tasten "Power" und "Lauter" drücken. Es erscheint ein weiteres Menü, das mit Android Recovery betitelt ist.
Mit "Leiser/Lauter" den Menüpunkt Wipe data/factory reset auswählen und mit "Power" bestätigen.
Die Daten auf dem Tablet werden gelöscht, was eine Weile dauert. Anschließend kehrt das System zum Ausgangsmenü zurück.
Nun den Menüpunkt Reboot system now auswählen. Das System startet neu. Nun kann die Neueinrichung durchgeführt werden.
Kein fataler Fehler:

![]()
Für die Ausführung von Programmen ist es oft notwendig, dass bestimmte Umgebungsvariablen gesetzt sind. Dies kann allgemeine Variablen betreffen, wie z.B. den Suchpfad PATH oder programmspezifische Variablen, wie z.B. ORACLE_HOME.
Die Frage ist, wie man eine Shell-Umgebung aufsetzt, so dass diese möglichst universell nutzbar ist, insbesondere, wenn Programme auch von außerhalb der eigenen interaktiven Sitzung, z.B. via cron, sudo oder ssh ausgeführt werden sollen.
Die Shell (bash, ksh, sh) führt bei jedem Login die nutzerspezifische Datei .profile aus. Werden in dieser Datei alle Environment-Variablen gesetzt (und exportiert), kann die Umgebung leicht in anderen Kontexten genutzt werden. Die Variablen in einer rc-Datei (.bashrc oder .kshrc) zu setzen ist verkehrt, da der Inhalt einer rc-Datei ausschließlich bei interaktiven Sitzungen ausgeführt wird und daher ausschließlich Definitionen enthalten sollte, die für eine Benutzerinteraktion mit der Shell relevant sind (Beispielsweise: Aussehen des Prompt, Aliase, Länge der History, Farben für ls(1), usw.).
Dies ist der normale Anwendungsfall. Eine Login-Shell wird gestartet und im Zuge dessen .profile ausgeführt.
Das Remote-Kommando ersetzt in diesem Fall die Login-Shell. Wir sorgen mit bash -l dafür, dass die Login-Umgebung hergestellt wird:
$ ssh USER@HOST "bash -lc 'COMMAND'"
Hier ist es wichtig, dass beim Öffnen des Terminals eine Login-Shell ausgeführt wird. Ggf. ist es nötig, hierfür eine Option in den Einstellungen zu aktivieren. In den Einstellungen des Xfce Terminals heißt die Option "Run command as login shell", ist per Default dekativert und sollte aktiviert werden.
Bei sudo sorgt die Option -i dafür, dass das Kommando an eine Login-Shell übergeben wird:
$ sudo -iu USER COMMAND
Wie bei der Ausführung eines Remote-Kommandos per ssh sorgen wir mit bash -l dafür, dass die Login-Umgebung vor Ausführung des Kommandos hergestellt wird.
* * * * * bash -lc COMMAND
Anstelle der bash nutzen wir sudo (wie oben):
* * * * * sudo -iu USER COMMAND
![]()
31.16.4.127 - - [15/Jul/2015:12:27:34 +0200] "GET /path/script.cgi?a=b HTTP/1.1" 302 583 "http://host.domain/page" "Mozilla/5.0 (X11; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0 Iceweasel/38.1.0"
Der Aufbau der access.log-Datei, die ein Apache HTTP-Server per Default schreibt, ist in mehrfacher Hinsicht suboptimal:
Information ist unpraktisch formatiert: Der Request-Zeitpunkt wird als [15/Jul/2015:12:27:34 +0200] (Formatelement %t) aufgezeichnet. Ein ISO-8601-ähnlicher Aufbau à la 2015-07-15 12:27:34 wäre besser lesbar und verarbeitbar. Zudem wird die Zeitzone im Normalfall nicht benötigt (da der Server ja nur in einer Zeitzone läuft, die bekannt sein sollte).
Information ist zusammengesetzt, die besser getrennt sein sollte: Der Request wird als eine Zeichenkette "GET /path/script.cgi?a=b HTTP/1.1" (Formatelement %r) aufgezeichnet. Darin sind vier Teilinformationen enthalten:
die Request-Methode (GET),
der URL-Pfad (/path/script.cgi),
der (optionale) Query-String (?a=b),
das Request-Protokoll (HTTP/1.1).
Eine Zerlegung ist nicht ganz einfach, da der Query-String optional ist. Besser wäre es, die Information in getrennten Feldern abzulegen (URL-Pfad und Query-String können zusammengelegt werden).
Interessante Information fehlt: Z.B. fehlt die Ausführungsdauer des Requests, die insbesondere bei der Performance-Optimierung von dynmisch generierten Inhalten hilfreich ist, sowie Hostname und Port, an die der Request gegangen ist, was bei einem VirtualHost-Setup von Nutzen sein kann. Auch der Content-Type der Response kann interessant sein, um Logeinträge danach filtern zu können.
Zeilen lassen sich schlecht in ihre Teilinformationen zerlegen: Eine einfache Trennung auf Whitespace geht nicht, da manche Felder Whitespace enthalten. Solche Felder sind in doppelte Anführungsstriche eingefasst. Aber nicht alle. Der Aufruf-Zeitpunkt ist in eckige Klammern eingefasst (s.o.). Fehlende Werte werden durch einen Bindstrich (-) dargestellt. Aber auch nicht immer. Für den Query-String (Formatelement %q) gilt dies nicht.
Aufgrund dieser Ungereimtheiten definiert man sich am besten ein eigenes Logfile-Format. Zum Glück ist dies mit der Apache-Direktive LogFormat leicht möglich. Ich verwende folgende Definition, mit einem senkrechten Strich als eindeutigem Feldtrenner:
LogFormat "%{%Y-%m-%d %H:%M:%S}t|%h|%>s|%L|%D|%I|%O|%{Content-Type}o|
%m|%v|%p|%U%q|%H|%{Referer}i|%{User-Agent}i" NAME
Verwendete Formatelemente (die mit + gekennzeichneten Informationen kommen im ursprünglichen Format nicht vor):
%{%Y-%m-%d %H:%M:%S}t Request-Zeitpunkt
%h .................. Client-IP oder -Name
%>s ................. finaler HTTP Status (200, ...)
%L .................. + error.log wurde geschrieben
%D .................. + Ausführungsdauer in Mikrosekunden
%I .................. + Bytes empfangen
%O .................. Bytes gesendet
%{Content-Type}o .... + Content-Type Header der Response
%m .................. Request-Methode (GET, POST, ...)
%v .................. + Hostname
%p .................. + Port
%U .................. URL-Pfad
%q .................. Query-String
%H .................. Request-Protokoll (HTTP/1.0, ...)
%{Referer}i ......... Referer Header des Requests
%{User-Agent}i ...... User-Agent Header des Requests
NAME ................ Name es Log-Formats
Ein weiteres interessantes Formatelement ist
%{COOKIE}C .......... + Wert des Cookie COOKIE
das in Anwendungen, die Cookies nutzen, nützlich sein kann. Ich füge es bei Bedarf am Ende hinzu.
Links:
2015-07-15 12:27:34|31.16.4.127|302|-|7273|400|583|text/html|GET|myhost.mydomain|80|/path/script.cgi?a=b|HTTP/1.1|http://host.domain/page|Mozilla/5.0 (X11; Linux x86_64; rv:38.0) Gecko/20100101 Firefox/38.0 Iceweasel/38.1.0

Wer Docker unter Debian installieren möchte, findet das Paket (docker-ce) nicht im Debian Repository, sondern muss es von einem Docker-Server installieren. Die entsprechende Installationsanleitung findet sich hier. Es gibt allerdings nur Pakete für die vergangenen Stable-Releases von Debian (Stretch, Jessie, Wheezy), nicht für das aktuelle Testing-Release (Buster). Das macht aber nichts, das Paket für das letzte Stable-Release (Stretch) funktioniert auch unter Buster.
Installation:
# apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common # curl -fsSL https://download.docker.com/linux/debian/gpg | apt-key add - # apt-key fingerprint 0EBFCD88 # vi /etc/apt/sources.list # die folgende Zeile hinzufügen deb [arch=amd64] https://download.docker.com/linux/debian stretch stable # apt-get update # apt-get install docker-ce
Test:
# docker run hello-world
Verzeichnisbaum mit den Docker-Bewegungsdaten:
/var/lib/docker
Füge user USER zur Gruppe docker hinzu, damit dieser neben root ebenfalls mit Docker arbeiten kann:
# usermod -G docker USER
Container starten:
$ docker run IMAGE
Container stoppen:
$ docker stop CONTAINER
Liste der aktuell ausgeführten Container:
$ docker ps
Liste aller Container, einschließlich der beendeten:
$ docker ps -a
Lösche einen oder mehrere Container:
$ docker rm CONTAINER ...
Lösche alle unbenutzten oder unreferenzierten Images, Container, Volumes und Networks:
$ docker system prune -a
Kommando im Container ausführen:
$ docker exec CONTAINER COMMAND ARG ...
Z.B.
$ docker run debian -d sleep 120 # -d = detach 06f0ee0e2256c5d531f8134f1bbb8f91b7189483c4ab21c4fb7807384420b1bf $ docker exec 06f0ee0e2256 cat /etc/hosts 127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1 ip6-allnodes ff02::2 ip6-allrouters 172.17.0.2 06f0ee0e2256
Stdin und stdout mit dem Container verbinden:
$ docker run -it IMAGE # -i = stdin, -t = stdout
Einen internen Port auf einen externen Port abbilden:
$ docker run -p PORT_EXTERN:PORT_INTERN IMAGE PORT_INTERN: Port innerhalb des Containers PORT_EXTERN: Port auf dem Docker-Host
Ein internes Verzeichnis auf ein externes Verzeichnis abbilden:
$ docker run -v DIR_EXTERN:DIR_INTERN IMAGE DIR_EXTERN: Verzeichnis auf dem Docker-Host DIR_INTERN: Verzeichnis innerhalb des Containers
Environement-Variablen setzen:
$docker run -e NAME=VALUE IMAGE
(die definierten Enviroment-Variablen: docker inspect IMAGE)
Logs auf stdout ausgeben:
$ docker logs CONTAINER
Image herunterladen:
$ docker pull IMAGE
Liste der lokal vorrätigen Images:
$ docker image ls
Lösche ein oder mehrere Images:
$ docker rmi IMAGE ...
Image-Konfiguration ansehen:
$ docker inspect IMAGE
Image in TAR speichern:
$ docker image save IMAGE >FILE.tar
Image in Dateisystem entpacken (mit dem Zusatzprogramm undocker):
$ docker image save IMAGE | undocker -o DIR
Image im globalen Repository (Docker Hub) suchen:
$ docker search TERM
Eigenes Image erstellen:
$ mkdir my-app $ cd my-app $ vi Dockerfile ... $ docker build -t my-app .
Beispiel:
FROM debian RUN apt-get update RUN apt-get -y install python3 RUN apt-get -y install python3-pip RUN pip3 install flask RUN pip3 install flask-mysql COPY . /opt/www ENTRYPOINT FLASK_APP=/opt/www/app.py flask run --host=0.0.0.0
Image erzeugen:
docker build . -t ACCOUNT/NAME
Beispiel:
$ docker build . -t s31tz/webapp $ docker run -p 5000:5000 s31tz/webapp
Erzeugungshistorie anzeigen:
$ docker history IMAGE
Alle Images entfernen, die von keinem Container genutzt werden:
$ docker image prune -a
Lokales Netz (Class B) erzeugen:
$ docker network create NAME
Liste der Netze:
$ docker network ls
Lösche ein oder mehrere Netze:
$ docker network rm
Globales Repository von Docker-Images (Account ist kostenlos):
Doku zu den offiziellen Docker-Images:

Wer Jenkins unter Debian installieren möchte, findet das Paket (jenkins) nicht im Debian Repository, sondern muss es von einem Jenkins-Server installieren.
# curl -fsSL http://pkg.jenkins-ci.org/debian/jenkins-ci.org.key | apt-key add - # echo deb http://pkg.jenkins-ci.org/debian binary/ >/etc/apt/sources.list.d/jenkins.list # apt-get update # apt-get install jenkins
Anschließend mit dem Browser auf http://localhost:8080 gehen, Jenkins mit Administrator-Passwort freischalten, mit "Install suggested plugins" den Standardsatz an Plugins installieren und die Installation mit der Einrichtung des ersten Administrator-Accounts abschließen.
Jenkins starten (findet bei der Installation automatisch statt):
# /etc/init.d/jenkins start
Jenkins stoppen:
# /etc/init.d/jenkins stop
Jenkins Homeverzeichnis (~jenkins):
/var/lib/jenkins
Jenkins läuft per Default auf Port 8080. Ein anderer Port kann in /etc/default/jenkins konfiguriert werden.
Wer seinen Browser auf Deutsch eingestellt hat, erhält bei Jenkins eine deutschsprachige Bedienoberfläche. Wer, wie ich, eine englischsprachige Bedienoberfläche bevorzugt, aber nicht die Browsersprache umstellen möchte, kann dies mit dem Plugin "Locale" erreichen:
Jenkins verwalten / Plugins verwalten -> Plugin "Locale" installieren
Jenkins verwalten / System konfigurieren -> Default Language: English + Ignore browser preference and force this language to all users
Anschließend ist die Bedienoberfläche auf englisch.
Damit Jenkins auf ein Git-Repository zugreifen kann, sind zwei Angaben nötig: 1. Der URL des Git-Repository, 2. Die Credentials für den Repository-Zugriff. Zum Beispiel:
Project Repository: ssh://fs2@localhost/~/try/jenkins/example01 Domain: Global credentials (unresticted) Kind: SSH Userkey with private key Scope: Global (Jenkins, nodes, items, etc.) Username: fs2 Private Key: from the jenkins master ~/.ssh
Schlüsselpaar für jenkins erzeugen und zu den authorized_keys des Repostitory-Owners fs2 hinzufügen:
# cd ~jenkins/.ssh # ssh-keygen -t rsa # chown jenkins.jenkins * # cat id_rsa.pub >>~fs2/.ssh/authorized_keys
Siehe auch: How to Setup Git Repository and Credentials for Jenkins Jobs
Damit Jenkins Docker-Operationen ausführen kann, muss der der Benutzer jenkins zur Gruppe docker hinzugefügt werden:
# usermod -G docker jenkins # /etc/init.d/jenkins restart
![]()
Wer sich als Admin mit Confluence befassen oder gegen die REST-Schnittstelle programmieren möchte oder einfach eine temporäre Testinstanz braucht, ohne selbst über eine Confluence-Instanz zu verfügen, kann sich beim Hersteller eine kostenlose Cloud-Instanz zulegen:
Confluence Cloud Server (free trial)
Nach dem Ausfüllen des Formulars und der Bestätigung einer Email steht einem eine Confluence Cloud-Instanz eine Woche kostenlos zur Verfügung. Danach kann man die Instanz kostenpflichtig weiter führen oder löschen.
CPAN::Mini installieren
$ cpanm CPAN::Mini
Konfigurationsdatei erstellen
$ vi ~/.minicpanrc local: MINICPAN remote: MIRROR exact_mirror: 1
Offline-Mirror aufbauen bzw. aktualisieren
$ minicpan
Ein Modul aus dem Offline-Mirror standardmäßig installieren
$ cpanm --mirror MINICPAN --mirror-only MODULE
oder "self contained" in ein bestimmtes Verzeichnis
$ cpanm --mirror MINICPAN --mirror-only -L DIR MODULE
Hierbei ist:
Der Pfad des Verzeichnisses, in dem wir unseren CPAN Offline-Mirror speichern, z.B. der Pfad eines gemounteten USB-Sticks.
Der URL des CPAN-Mirrors, aus dem wir unseren Offline-Mirror befüllen (Liste der verfügbaren Sites siehe http://www.cpan.org/SITES.html).
Ein Perl-Modul, das wir aus unserem Offline-Mirror installieren.
Ein lokales Verzeichnis, in das wir Perl-Module installieren.
![]()
MP3-Dateien können mit dem concat-Protokoll konkateniert werden, die Bitraten müssen nicht übereinstimmen:
$ ffmpeg -i "concat:INPUT1.mp3|INPUT2.mp3|..." -c copy OUTPUT.mp3
![]()
Über die Plugin-Schnittstelle kann Mojolicious oder eine Mojolicious-Applikation um jede denkbare Funktionalität erweitert werden. Die Plugin-Schnittstelle ist sehr einfach gehalten. Denn sie gibt nur vor, wie eine Funktionalität zum System hinzugefügt wird, nicht jedoch, um welche Art von Funktionalität es sich handelt.
Die Implementierung eines Mojolicious-Plugin erfolgt in zwei Schritten:
Durch Ableitung von Mojolicious::Plugin wird eine Subklasse - die Plugin-Klasse - gebildet.
In der Plugin-Klasse wird die Methode register() implementiert.
In der Dokumentation zur Basisklasse Mojolicious::Plugin wird die Implementierung so beschrieben:
package Mojolicious::Plugin::MyPlugin;
use Mojo::Base 'Mojolicious::Plugin';
sub register {
my ($self, $app, $conf) = @_;
# Magic here! :)
}
Der Aufwand der Plugin-Implementierung besteht natürlich darin, den mit
# Magic here! :)
bezeichneten Teil mit Leben zu füllen.
Ist das Plugin implementiert, wird es durch einen einzigen Aufruf zur Applikation hinzugefügt:
$app->plugin(MyPlugin => \%config);
Der analoge Aufruf unter Mojolicious::Lite:
plugin MyPlugin => \%config;
Hierbei ist %config ein Hash mit Schlüssel/Wert-Paaren - typischerweise als Hash-Literal angegeben - durch den das Plugin konfiguriert wird. Ist keine Konfigurierung des Plugin nötig, kann das Argument weggelassen werden.
Als einfaches Beispiel implementieren wir ein Plugin Hello, das bei jedem hereinkommenden Request die Zeichenkette 'Hello' und die IP-Adresse des Aufrufers ins Log ausgibt. Dies erreichen wir, indem wir in der Methode register() einen before_routes-Handler aufsetzen, der genau dies tut.
package Mojolicious::Plugin::Hello;
Mojo::Base 'Mojolicious::Plugin';
sub register {
my ($self, $app, $conf) = @_;
$app->hook(before_routes=>sub {
my $c = shift;
$c->app->log->debug('Hello '.$c->tx->remote_address);
});
return;
}
Das Plugin wird durch
$app->plugin('Hello');
oder im Falle von Mojolicious::Lite durch
plugin 'Hello';
in der Applikation aktiviert. Eine Konfiguration ist bei den Aufrufen nicht angegeben, da das Plugin keine Konfigurierungsmöglichkeit vorsieht.
![]()
Konfigurationsprogramm des Druckers unter seiner IP im lokalen Netz, z.B. http://192.168.178.24/
HPLIB (HP Linux Imaging and Printing) installieren:
# apt-get install hplip hplib-gui hplib-doc
Lokale Dokumentation: file:///usr/share/doc/hplip-doc/index.html
Überprüfung der Abhängigkeiten, Permissions etc. von HPLIP und Nachinstallation von fehlenden Paketen (dies ist in diesem speziellen Fall durch die Installation per apt-get - was ungewöhnlich ist - nicht sicher gestellt):
$ hp-check
Verfügbarkeit des Druckers via USB, Ethernet, WLAN prüfen:
$ hp-probe
Treiber des Druckers herunterladen und Drucker und Fax rudimentär einrichten:
$ hp-setup -i
HP Device Manger:
$ hp-toolbox
Der Drucker unter CUPS: http://localhost:631
Drucker zum Default-Drucker machen (für lpr/lpq):
$ lpoptions -d PRINTER
Mit dem Programm hp-scan kann vom Flachbett oder über den Dokumenteneinzug gescannt und das Ergebnis lokal gespeichert werden, ohne mit einem USB-Stick hantieren zu müssen. Außerdem hat das Programm diverse Optionen, mit denen auf das Scan-Ergebnis Einfluss genommen werden kann ($ man hp-scan).
Beispiel: Scanne alle A4-Seiten (--size=a4), die auf der automatischen Dokumentenzufuhr (--adf) eingelegt sind in Farbe (--mode=color) mit 150 DPI (--resolution=150) und füge sie zu einem PDF-Dokument (Dateiendung .pdf) zusammen:
$ hp-scan --adf --size=a4 --mode=color --resolution=150 --file=FILE.pdf
Im Falle von PDF sind die Auflösungen 75, 100, 150, 200, 300 DPI möglich, bei JPG oder PNG bis zu 1200 DPI.

Header mit beliebigem Inhalt:
| 1 | <div id="header"> |
| 2 | CONTENT |
| 3 | </div> |
Header am Seitenanfang fixieren:
| 1 | #header { |
| 2 | position: fixed; |
| 3 | top: 0; |
| 4 | width: 100%; |
| 5 | z-index: 1; |
| 6 | background-color: COLOR; |
| 7 | } |
Am Seitenanfang Platz für den fixierten Header reservieren:
| 1 | $(function () { |
| 2 | $('body').css('margin-top',$('#header').outerHeight()); |
| 3 | }); |
Demo:

Die jQuery UI Widgets Tabs und Accordion könnten - bis auf die Ausrichtung ihrer Reiter (Tabs horizontal, Accordion vertikal) - identisch sein. Sind sie aber nicht. Während das Tabs-Widget das Laden von Inhalten per Ajax direkt unterstützt, ist dies beim Accordion-Widget nicht vorgesehen. Es ist jedoch möglich, dies durch einen beforeActivate Event-Handler und bestimmte Einstellungen zu realisieren.
<div id="ID">
<h3><a href="URL">TITLE</a></h3>
<div></div>
...
</div>
ID ist die DOM-Id des Accordion. Der TITLE des Reiters wird in einen a-Tag eingefasst, dessen href-Attribut den URL definiert, von dem wir den Inhalt des Accordion-Panel per Ajax abrufen. Der div-Container für den Panel-Content ist leer, dieser wird per Ajax gefüllt.
$('#ID').accordion({
beforeActivate: function (event,ui) {
var url = ui.newHeader.find('a').attr('href');
if (url)
ui.newPanel.load(url);
},
active: false,
collapsible: true,
heightStyle: 'content'
});
Das Laden des Panel-Inhalts per Ajax realisiert der beforeActivate-Handler, den wir bei der Instanziierung des Accordion-Widget definieren (Zeilen 2-6). Wir nutzen den beforeActivate-Handler und nicht den activate-Handler, da er vor dem Öffnen des Reiters gerufen wird. D.h. zum Zeitpunkt des Öffnens ist der Inhalt bereits geladen, was einen flüssigen Ablauf ergibt.
Die Setzungen
active: false collapsible: true
bewirken in dieser Kombination, dass zunächst alle Reiter geschlossen bleiben, denn das initiale Öffnen feuert nicht die beforeActivate- und activate-Events. Das initiale Öffnen realisieren wir durch das Auslösen eines Click-Event nach der Accordion-Instanziierung (s.u.).
Die Setzung
heightStyle: 'content'
bewirkt, dass die Höhe des Panel automatisch an den geladenen Inhalt angepasst wird. Dies ist wichtig, da der Inhalt vorab nicht bekannt ist.
$('#ID a:first').trigger('click');
Den ersten Accordion-Reiter öffnen wir durch das Auslösen eines Click-Event, so als hätte der Anwender auf den ersten Reiter geklickt. Auf diese Weise ist sichergestellt, dass der beforeActivate-Handler gerufen und damit der Inhalt geladen wird.
Links:
![]()
Mit der Class Option hover kann beim jQuery Plug-In DataTables eingestellt werden, dass die Tabellen-Zeile unter der Maus hervorgehoben wird. Leider ist die Hervorhebung so schwach, dass sie in Kombination mit Class Option stripe auf den dunkleren Zeilen kaum sichtbar ist.
Hier der CSS-Code, mit dem sich die Hover-Farbe ändern lässt:
#ID.dataTable.hover tbody tr:hover, #ID.dataTable.display tbody tr:hover { background-color: COLOR; }
Hierbei ist ID die DOM-Id der Tabelle und COLOR die gewünschte Farbe. Die Hover-Farbe ist per Default auf das sehr helle Grau #f6f6f6 eingestellt. Wählt man z.B. das dunklere #e8e8e8, ist die Hervorhebung deutlich erkennbar.
Soll die Hover-Farbe für alle DataTables gelten:
table.dataTable.hover tbody tr:hover, table.dataTable.display tbody tr:hover { background-color: COLOR; }
![]()
Ein leistungsfähiges jQuery Plug-In für Tabellen ist DataTables. Es kann in vielfältiger Weise konfiguriert werden. Einige Anpassungen im Zusammenhang mit dem Filter-Suchfeld sind allerdings schlecht dokumentiert. Das Filter-Suchfeld ist per Default mit dem Label-Text "Search:" beschriftet und befindet sich rechts über der Tabelle. Hier eine kurze Beschreibung, wie dieses Setup geändert werden kann. Im folgenden Code stehen ID, LABEL und WIDTH für die frei wählbaren Angaben DOM-Id der Tabelle, Label-Text und CSS-Breite.
Label-Text setzen (JS):
$('#ID').DataTable({
...
'language': {
'search': 'LABEL'
}
});
Suchfeld links positionieren (CSS):
#ID_filter {
float: left;
}
Suchfeld mittig positionieren (CSS):
#ID_filter {
width: 100%;
text-align: center;
}
Größe des Suchfelds ändern (CSS):
#ID_filter input[type="search"] {
width: WIDTH;
}
Eigenes Suchfeld definieren:
<input type="text" id="searchField" ...>
$('#searchField').on('keyup',function () {
tab.search(this.value).draw();
});
Das von DataTables erzeugte Suchfeld unterdrücken:
$('#ID').DataTable({
dom: 't', // nur die Tabelle selbst, ohne Suchfeld etc.
...
});
![]()
Gegeben ein Perl-Projekt myproject mit einem eigenen Projektverzeichnis PREFIX/myproject und einer Unix-typischen Unterverzeichnisstruktur mit den Verzeichnissen bin, lib usw.
PREFIX/myproject/bin/myprogram
lib/perl5/MyClass.pm
...
PREFIX ist ein beliebiger Verzeichnis-Pfad. Im Unterverzeichnis bin sind die Programme des Projektes installiert (hier ein Programm myprogram) und in Unterverzeichnis lib/perl5 die Module des Projektes (hier ein Modul MyClass.pm).
Wir wollen das Programm myprogram nun außerhalb des Projektbaums verfügbar machen, z.B. damit es über einen allgemeinen Suchpfad aufrufbar ist, oder - falls es ein CGI-Programm ist - um es in eine Web-Verzeichnisstruktur einzufügen, ohne dass wir einen ScripAlias definieren können oder wollen.
Das Problem: Außerhalb des Projektbaums installiert verliert das Programm den Bezug zum Projektverzeichnis und kann die anderen Verzeichnisse des Baums, wie z.B. das Modulverzeichnis lib/perl5 nicht ohne Weiteres adressieren. Man könnte den Pfad zum Projektverzeichnis auf einer Environment-Variablen definieren, aber das ist umständlich.
Ein eleganterer Weg ist, das Programm per Symlink außerhalb des Projektbaums zu installieren und den realen Installationspfad des Programms mittels der Variable $RealBin des (Core-)Moduls FindBin zu ermitteln.
$ ln -s PREFIX/myproject/bin/myprogram /usr/local/bin/myprogram
Am Anfang von myprogram, vor dem Laden des projektspezifischen Moduls MyClass, fügen wir die beiden Zeilen ein:
use FindBin qw/$RealBin/; use lib "$RealBin/../lib/perl5"; use MyClass;
Der Pfad $RealBin ist das Verzeichnis, in dem das aufgerufene Programm sich befindet, und zwar nach Auflösung aller Symlinks. D.h. der Pfad ist stets
PREFIX/myproject/bin
auch wenn das Programm über den Pfad /usr/local/bin/myprogram aufgerufen wird.
![]()
Der reinen Datenbank-Lehre nach ist es strikt verboten mehrere Werte auf einem Attribut zu speichern. Sowas kommt in der Realität trotzdem vor, sogar bei Fremdschlüssel-Attributen. D.h. das Fremdschlüssel-Attribut referenziert in dem Fall nicht nur eine, sondern mehrere Zeilen. Die gute Nachricht ist, dass MySQL es erlaubt, für so ein - ansich unterlaubtes - Design mithilfe der Funktion find_in_set() eine Join-Condition zu formulieren.
Gegeben zwei Tabellen TableA und TableB, wobei Attribut TableB.tablea_id auf mehrere Zeilen in TableA verweist.
TableA TableB id id tablea_id -- -- --------- 1 1 2,3 2 2 3 3 3 1,2,3,4 4 4 NULL
Wäre TableB.tablea_id ein normales Fremdschlüssel-Attribut mit einem Wert sähe die Join-Condition so aus:
TableA.id = TableB.tablea_id
Diese Bedingung ist hier nicht anwendbar, da eine Identität (=) zwischen TableA.id und TableB.tablea_id nur manchmal gegeben ist.
Die Selektion
SELECT
b.id b_id
, a.id a_id
FROM
TableA a
INNER JOIN TableB b
ON a.id = b.tablea_id
ORDER BY
b.id
, a.id
liefert ein falsches Resultat
+------+------+ b_id | a_id | +------+------+ | 1 | 2 | zweifelhaft | 2 | 3 | erwartet | 3 | 1 | zweifelhaft +------+------+
Da MySQL bei numerischen Identitäts-Vergleichen eine laxe Auffassung hat und gegen den numerischen Anfang einer Zeichenkette vergleicht, auch wenn die Zeichenkette insgesamt keine Zahl darstellt, ist die Ergebnismenge zusätzlich zweifelhaft. Statt der erwarten einen Zeile werden drei Zeilen geliefert.
MySQL besitzt jedoch eine Funktion find_in_set(), mit deren Hilfe eine Join-Condition formuliert werden kann, die die mehrwertigen Verweise korrekt auflöst:
FIND_IN_SET(TableA.id, TableB.tablea_id) > 0
Die Selektion
SELECT
b.id b_id
, a.id a_id
FROM
TableA a
INNER JOIN TableB b
ON FIND_IN_SET(a.id, b.tablea_id) > 0
ORDER BY
b.id
, a.id
liefert das korrekte Resultat
+------+------+ b_id | a_id | +------+------+ | 1 | 2 | | 1 | 3 | | 2 | 3 | | 3 | 1 | | 3 | 2 | | 3 | 3 | | 3 | 4 | +------+------+

TeamViewer kann nicht per apt-get installiert werden. Das Debian-Paket muss stattdessen von der Download-Seite des Herstellers heruntergeladen und manuell installiert werden. Zu beachten ist, dass auf neueren 64bit-Debian-Systemen (mit Multiarch-Support) das i386-Paket installiert werden muss (siehe "Hinweise zur Installation" auf der Download-Seite).
Debian-Paket von Download-Seite herunterladen. Der Dateiname lautet aktuell teamviewer_11.0.53191_i386.deb.
# dpkg --add-architecture i386 # apt-get update # gdebi teamviewer_11.0.53191_i386.deb ... Do you want to install the software package? [y/N]:y ...
Sollte gdebi nicht installiert sein, kann dies mit
# apt-get install gdebi
nachgeholt werden. Das Programm installiert lokal vorliegende Debian-Pakete und löst automatisch alle Abhängigkeiten auf (was dpkg -i nicht macht).
Es kommt vor, dass der TeamViewer-Client keine Connection herstellen kann und die Meldung anzeigt
Not ready. Check your connection.
Dies lässt sich u.U. durch einen Neustart des Dämons beheben
# teamviewer daemon restart
![]()
Entferne POD-Abschnitte aus Perl-Quelltext:
$src =~ s/^=[a-z].*?^=cut\n*//msg;
Entferne ganzzeilige Kommentare aus Perl-Quelltext:
$src =~ s/^[\t ]*#.*\n+//mg;
Entferne teilzeilige Kommentare aus Perl-Quelltext:
$src =~ s/[\t ]+# .*//g;
Diese Operationen sind nützlich, wenn man einen Perl-Quelltext ohne Dokumentation und Kommentare ausliefern möchte, oder wenn man entscheiden möchte, ob eine Quelltextänderung getestet werden muss. Letzteres ist ratsam, wenn Änderungen in dem Teil des Quelltextes existieren, der übrig bleibt, wenn man die Dokumentation und die Kommentare entfernt.
Als teilzeiliger Kommentar wird die Abfolge WHITESPACE-HASH-SPACE-TEXT akzeptiert. Ein teilzeiliger Kommentar muss entsprechend verfasst sein, sonst wird er nicht entfernt. Diese Einschränkung hat den Zweck, Fehl-Erkennungen zu vermeiden, denn
$src =~ s/#.*//g;
wäre gefährlich, da dieser Regex nach jedem HASH abschneidet. Siehe auch folgende Warnung.
Warnung: Ohne echtes Parsing gemäß der Grammatik einer Sprache sind absolut sichere Operationen auf einem Quelltext nicht möglich - insbesondere bei Perl, das eine sehr facettenreiche Syntax hat. Obige Pattern können in besonderen Fällen den Inhalt von String-Literalen matchen. Im Einzelfall kann so eine Fehl-Erkennung durch Änderung des Literals - z.B. durch Einstreuen von Backslashes - verhindert werden.
![]()
Anforderung: Ein Hash-Objekt besitzt ein Attribut theAttribute, das von einer gleichnamigen Attributmethode gekapselt wird. Das Attribut erhält bei der Objekt-Instanziierung keinen Wert. Der Wert wird stattdessen beim ersten Zugriff berechnet. Alle weiteren Zugriffe liefern den berechneten Wert.
Ein naheliegender Ansatz, dies in Perl zu implementieren, ist:
| 1 | sub theAttribute { |
| 2 | my $self = shift; |
| 3 | |
| 4 | if (!defined $self->{'theAttribute'}) { |
| 5 | ... |
| 6 | $self->{'theAttribute'} = $val; |
| 7 | } |
| 8 | |
| 9 | return $self->{'theAttribute'}; |
| 10 | } |
Hierbei ist $val der in Abschnitt ... berechnete Attributwert (der auf dem Attribut gecached wird).
Diese Lösung ist relativ hässlich, da der Ausdruck
$self->{'theAttribute'}
gleich drei Mal auftaucht.
Zum Glück lässt sich die Sache auch eleganter formulieren:
| 1 | sub theAttribute { |
| 2 | my $self = shift; |
| 3 | |
| 4 | return $self->{'theAttribute'} //= do { |
| 5 | ... |
| 6 | $val; |
| 7 | }; |
| 8 | } |
Erklärung: Ist der Wert von theAttribute definiert, wird er unmittelbar geliefert. Ist er nicht definiert, wird der do-Block ausgeführt. Dessen Wert wird erst an das Attribut zugewiesen (=) und dann von der Methode geliefert (return). Den Defined-Or-Operator // gibt es seit Perl 5.10.
Ist die Objektstruktur komplexer als ein Hash, lässt sich die Semantik von
$self->{$key} //= do { ... };
auch als Objektmethode mit einer anonymen Subroutine als Parameter realisieren:
| 1 | sub memoize { |
| 2 | my ($self,$key,$sub) = @_; |
| 3 | |
| 4 | my $val = $self->get($key); |
| 5 | if (!defined $val) { |
| 6 | $val = $self->$sub($key); |
| 7 | $self->set($key=>$val); |
| 8 | } |
| 9 | |
| 10 | return $val; |
| 11 | } |
Hierbei sind get() und set() die Methoden zum Abfragen und Setzen des Attributwerts. Natürlich kann der Zugriff auf das Attribut - in Abhängigkeit von der Klasse - auch anders realisert sein.
Angewendet auf obiges Beispiel:
| 1 | sub theAttribute { |
| 2 | my $self = shift; |
| 3 | |
| 4 | return $self->memoize('theAttribute',sub { |
| 5 | ... |
| 6 | $val; |
| 7 | }); |
| 8 | } |
![]()
Finde innerhalb des Dateibaums DIR alle Vorkommen des Wortmusters REGEX und gib die Wortliste sortiert aus (GNU grep):
$ grep -oPhr REGEX DIR | sort | uniq
Soll die Menge der Dateien näher eingeschränkt werden, lässt sich dies durch ein vorgeschaltetes find erreichen (Option -r bei grep entfällt dann):
$ find DIR -type f -print0 | xargs -0 grep -oPh REGEX | sort | uniq
Finde in Dateibaum app mit Perl-Quelltexten die Namen aller verwendeten Klassen, die mit "R1::" beginnen:
$ grep -oPhr 'R1::[:\w]+' app | sort | uniq R1::AppHome R1::Array R1::CheckValue R1::ClassLoader R1::Config R1::Dbms::Database ...
![]()
Manchmal möchte man für ein Perl-Programm wissen, woher genau der Perl-Interpreter die Module lädt. Aus dem laufenden Programm heraus lässt sich dies mit folgender Zeile bestimmen:
say join "\n",sort values %INC;
Dasselbe mit print:
print join("\n",sort values %INC),"\n";
Die Anweisung gibt die Liste der Pfade aller geladenen Module sortiert aus.
Dasselbe auf der Kommandozeile, falls einen interessiert, welche Module ein bestimmtes Modul <MODULE> lädt:
$ perl -M5.010 -M<MODULE> -e 'say join "\n",sort values %INC'
![]()
Mitunter möchte man wissen, ob ein bestimmter Host erreichbar ist, z.B. vor Beginn von Regressionstests gegen Services des Hosts. Diese Prüfung kann in Perl mittels des Core-Moduls Net::Ping durchgeführt werden.
use Net::Ping;
my $p = Net::Ping->new;
my $isAlive = $p->ping($host);
$p->close;
if ($isAlive) {
print "Host $host ist erreichbar\n";
}
Per Default versucht die Klasse via TCP eine Verbindung zum echo-Port aufzubauen. Für andere Möglichkeiten (Test per UDP, ICMP, ...) siehe Doku.

Für die Skalierung von Grafik-Elementen, die in Ground Overlays für Google Earth platziert werden sollten, stand ich vor der Notwendigkeit, Abstände auf der Erdoberfläche berechnen zu müssen. Die folgende Gleichung hat mir dies ermöglicht.
Entfernung (in km) zwischen zwei Punkten auf der Erdoberfläche:
![]()
Die Gleichung liefert die Länge des Großkeisbogens zwischen zwei Punkten (lat1, lon1) und (lat2, lon2) auf einer Kugel mit einem Radius von 6371 Kilometern. Da die Erde keine perfekte Kugel ist (6371 km ist der mittlere Radius), stellt die Berechnung eine Näherung dar, die vor allem für größere Distanzen geeignet ist. Möchte man die Seemeile (= 1,852 km) als fundamentales Abstandsmaß für das Geosystem zugrundelegen (der geliefert Wert ist nach wie vor km, aber der Erdumfang wird als das 60*360-fache einer Seemeile definiert), ersetzt man 6371 durch
![]()
Die Formel geht davon aus, dass die trigonometrischen Funktionen acos(), sin(), cos() im Bogenmaß (rad) rechnen, was für Programmiersprachen typischerweise der Fall ist. Liegen lat1, lon1, lat2, lon2 in Grad vor, was bei Geopositionen üblich ist, müssen diese vor der Einsetzung ins Bogenmaß umgerechnet, also mit Pi/180 multipliziert werden.
![]()
Begründung und Herleitung der Formel: Blog Martin Kompf - Entfernungsberechnung
![]()
Mitunter soll das erste Element eines HTML-Konstrukts per CSS speziell gestaltet werden, z.B. was dessen Außenabstände angeht. Diese Anforderung gibt es in zwei Ausprägungen:
Das zu behandelnde Element ist das erste Element, das dem Bezugselement folgt.
Das zu behandelnde Element ist das erste Element, das dem Bezugselement untergeordnet ist.
Diese beiden Element-Anordnungen erfordern unterschiedliche CSS-Selektoren.
<X>...</X>
<Y>
...
</Y>
...
Der CSS-Selektor lautet:
X + * {
...
}
Bezugselement ist X. Der Selektor + selektiert das unmittelbar folgende Element. Der Universelle Selektor * füllt hier syntaktisch die zweite Argumentposition des Selektors und nimmt keine weitere Einschränkung vor.
Beispiel: Jedes erste Element nach einer <h1>-Überschrift soll einen oberen Außenabstand von 0.5em erhalten:
h1 + * {
margin-top: 0.5em;
}
<X>
<Y>
...
</Y>
</X>
Der CSS-Selektor lautet:
X > *:first-child {
...
}
Bezugselement ist X. Der Selektor > selektiert alle Elemente, die dem Bezugselement direkt untergeordnet sind. Die Pseudoklasse *:first-child schränkt diese Menge auf das erste Kindelement ein (der Stern kann auch weggelassen werden).
Beispiel: Jedes erste Unterelement <Y> eines <dd>-Definitionsabschnitts soll keinen oberen Außenabstand besitzen, sondern direkt an den Definitionsterminus <dt> anschließen:
HTML:
<dl>
<dt>...</dt>
<dd>
<Y>
...
</Y>
</dd>
...
</dl>
CSS:
dd > *:first-child {
margin-top: 0;
}
![]()
Eine Datei per HTTP-Response mit Dateinamens-Vorschlag FILE_NAME vom Server zum Client zu transferieren geht so:
Per Location Redirection
Location: URL Content-Disposition: attachment; filename="FILE_NAME"
Per direkter Übertragung
Content-Type: TYPE/SUBTYPE Content-Disposition: attachment; filename="FILE_NAME" FILE_CONTENT
Die direkte Übertragung hat den Vorteil, dass die Datei nach dem Download serverseitig sofort gelöscht werden kann, falls sie nicht mehr gebraucht wird. Das ist bei einer Location Redirection nicht möglich, da der Client sie asynchron abruft.
![]()
Idealerweise sollte ein Programm sowohl mit ISO-8859-1 als auch mit UTF-8 Input-Dateien umgehen können, und zwar am besten so, dass das Encoding nicht explizit angegeben werden muss.
Lässt sich dies realisieren?
Ja, indem das Programm sich den Inhalt der Datei "ansieht", entscheidet, welches Encoding vorliegt und den Text entsprechend dekodiert.
Im Falle von Perl kann hierfür das Modul Encode::Guess genutzt werden. Es ist Teil des Perl-Core und damit in jeder Perl-Installation enthalten. Es wird mit
use Encode::Guess;
geladen.
Wir nutzen die objektorientierte Schnittstelle des Moduls. Theoretisch sollte folgender Sechszeiler die Aufgabe erledigen:
Encode::Guess->set_suspects('iso-8859-1');
my $dec = Encode::Guess->guess($text);
if (!ref $dec) {
die "ERROR: $dec\n";
}
$text = $dec->decode($text);
Erläuterung:
Wir definieren iso-8859-1 als Encoding, das zusätzlich zu den Default-Encodings ascii, utf8, UTF-16/32 mit BOM, geprüft werden soll.
Der Inhalt der Datei steht auf der Variable $text (das Einlesen hat vorher stattgefunden und ist hier nicht wiedergegeben). Die Methode guess() versucht das Encoding zu ermitteln und liefert im Erfolgsfall ein passendes Decoder-Objekt. Im Fehlerfall liefert die Methode eine Fehlermeldung (also eine Zeichenkette).
Fehlerbehandlung. Falls wir eine Fehlermeldung erhalten, brechen wir mit einer Exception ab. Zwei mögliche Fehlerfälle sind:
Der Text entspricht keinem der geprüften Encodings.
Mehr als eines der Encodings kommt infrage.
Es wurde ein Decoder-Objekt geliefert, also ein Encoding eindeutig erkannt. Wir dekodieren den Text mit dem Decoder-Objekt.
Leider funktioniert diese Implementierung nicht!
Denn wir stellen folgendes fest:
Ist die Datei ISO-8859-1 kodiert, gelingt das Dekodieren.
Ist die Datei UTF-8 kodiert, bricht der Code mit der Fehlermeldung
ERROR: utf8 or iso-8859-1
ab, d.h. der Methode guess() war es nicht möglich, das Encoding eindeutig zu bestimmen.
Woran liegt das?
Die Ursache ist, dass jede UTF-8-Datei formal auch eine ISO-8859-1-Datei ist. Denn jede Datei ist formal eine ISO-8859-1-Datei, selbst eine Binärdatei wie z.B. ein JPEG-Bild. Das liegt daran, dass ISO-8859-1 ein Ein-Byte-Encoding ist, bei dem alle 256 Werte belegt sind.
Es ist also fruchtlos und hinderlich, mit Encode::Guess auf ISO-8859-1 testen zu wollen.
Ist die Unterscheidung von UTF-8 und ISO-8859-1 also nicht möglich?
Doch, sie ist möglich, wenn auch nicht mit den Mechanismen von Encode::Guess allein. Denn auch wenn UTF-8 formal gültiges ISO-8859-1 darstellt, gilt nicht die Umkehrung, dass jeder ISO-8859-1 Text valides UTF-8 darstellt. Es ist sogar sehr unwahrscheinlich, dass ein realer ISO-8859-1 Text, gleichzeitig valides UTF-8 ergibt, beinahe ebensowenig, wie dass ein ISO-8859-1 Text ein JPEG-Bild ergibt.
Unter Berücksichtigung dieser Tatsache können wir die Unterscheidung von ISO-8859-1 und UTF-8 hinreichend sicher vornehmen:
my $dec = Encode::Guess->guess($text);
if (ref $dec) {
$text = $dec->decode($text);
}
elsif ($dec =~ /No appropriate encodings found/i) {
$text = Encode::decode('iso-8859-1',$text);
}
else {
die "ERROR: $dec\n";
}
Erläuterung:
Der Dateiinhalt wird auf die Default-Encodings ascii, utf8, UTF-16/32 mit BOM - also Unicode - geprüft.
Falls UTF-8 erkannt wurde (oder eines der anderen Unicode-Encodings) nutzen wir das gelieferte Encoder-Objekt um den Text zu dekodieren.
Falls kein Unicode-Encoding erkannt wurde, muss es sich um eine ISO-8859-1 Datei handeln, denn andere Encodings erwarten wir nicht. Wir dekodieren den Text ohne Encoder-Objekt (alternativ) mit der Funktion Encode::decode().
Falls ein sonstiger Fehler eingetreten ist, brechen wir mit einer Exception ab.
Dieser Ansatz ("Wenn etwas nach UTF-8 aussieht, ist es auch UTF-8, sonst betrachten wir es als ISO-8859-1") funktioniert.
Das Ganze als vollständige Implementierung einer Perl-Klasse File mit einer einzelnen Methode decode():
package File;
use strict;
use warnings;
use Encode::Guess ();
# ---------------------------------------------------------------------------
=encoding utf8
=head1 NAME
File - Klasse mit Datei-Operationen
=head1 METHODS
=head2 decode() - Lies und dekodiere eine Textdatei
=head3 Synopsis
$text = $class->decode($file);
=head3 Description
Lies Textdatei $file und liefere den dekodierten Inhalt zurück.
Als Character Encoding erwarten wir Unicode (speziell UTF-8) oder
Latin1 (ISO-8859-1).
=cut
# ---------------------------------------------------------------------------
sub decode {
my ($class,$file) = @_;
# Datei einlesen
local $/ = undef;
open my $fh,'<',$file or die "ERROR: open failed: $file ($!)\n";
my $text = <$fh>;
close $fh;
# Encoding ermitteln und Text dekodieren
my $dec = Encode::Guess->guess($text);
if (ref $dec) {
# Wir dekodieren Unicode
$text = $dec->decode($text);
}
elsif ($dec =~ /No appropriate encodings found/i) {
# Erwarteter Fehler: Wir dekodieren Latin1
$text = Encode::decode('iso-8859-1',$text);
}
else {
# Unerwarteter Fehler
die "ERROR: $dec\n";
}
return $text;
}
# ---------------------------------------------------------------------------
=head1 AUTHOR
Frank Seitz, L<http://fseitz.de/>
=head1 LICENSE
This code is free software. You can redistribute it and/or modify
it under the same terms as Perl itself.
=cut
# ---------------------------------------------------------------------------
1;
# eof
![]()
Ein hervorragendes Werkzeug zum Installieren von Perl-Modulen ist cpanm ("cpanminus").
Nach dem Kompilieren und Installieren von Perl aus den Quellen per
$ ./Configure -des -Dprefix=~ $ make test $ make install
und der Installation von cpanm per
$ curl -L http://cpanmin.us | `which perl` - --self-upgrade
kann man jedes (naja, fast jedes) CPAN-Modul mit einem simplen Aufruf zur Installation hinzufügen:
$ ~/bin/cpanm MODULE
Abhängkeiten von anderen Modulen werden erkannt und rekursiv aufgelöst.
Das Programm cpanm lässt sich auch standalone an Ort und Stelle installieren (aus App::cpanminus):
cd ~/bin curl -LO http://xrl.us/cpanm chmod +x cpanm # edit shebang if you don't have /usr/bin/env
Modul MODULE mit allen zusätzlich benötigten (non-core) Modulen in Verzeichnis DIR installieren, um sie auf eine andere Maschine zu übertragen:
$ cpanm -L DIR MODULE
Z.B.
$ cpanm -L perl5 File::Rsync --> Working on File::Rsync Fetching http://www.cpan.org/authors/id/L/LE/LEAKIN/File-Rsync-0.49.tar.gz ... OK Configuring File-Rsync-0.49 ... OK ==> Found dependencies: IPC::Run3 --> Working on IPC::Run3 Fetching http://www.cpan.org/authors/id/R/RJ/RJBS/IPC-Run3-0.048.tar.gz ... OK Configuring IPC-Run3-0.048 ... OK Building and testing IPC-Run3-0.048 ... OK Successfully installed IPC-Run3-0.048 Building and testing File-Rsync-0.49 ... OK Successfully installed File-Rsync-0.49 2 distributions installed
![]()
Ein Kommandozeilen-Werkzeug aus dem GNU-Werkzeugkasten zum Wandeln von Text nach PostScript, und damit in ein druckbares Format, ist enscript. Sein Verhalten wird von Konfigurationseinstellungen und den Kommandozeilenparametern des jeweiligen Aufrufs bestimmt.
Das Programm ist als Filter konzipiert, sendet seine Ausgabe per Default jedoch direkt an einen Drucker. Dieses Verhalten ist, wenn man enscript universell einsetzen will, eher störend. Es empfiehlt sich, in der Konfiguration "DefaultOutputMethod: stdout" einzustellen (s.u.), dann schreibt das Programm seine Ausgabe nach stdout. Im folgenden gehe ich von dieser Einstellung aus.
(Quell)Textdatei FILE in eine PDF-Datei wandeln:
$ enscript FILE | ps2pdf - FILE.pdf
Mit einem PDF-Viewer kann das Resultat FILE.pdf angesehen und von dort aus ganz oder teilweise gedruckt werden.
Enscript hat viele Optionen und Konfigurationsvariablen, mit denen man auf die Gestaltung der Druckseite Einfluss nehmen kann. Wie üblich, muss man ein wenig experimentieren bis das Ergebnis den eigenen Vorstellungen entspricht. Es folgen die Optionen, die ich für eine Quelltextausgabe als sinnvoll erachte.
Wer (wie ich) die Zeilenlänge seiner Quelltexte auf 80 Zeichen beschränkt, fährt mit einer zweispaltigen Ausgabe im Querformat am besten:
--columns=2 --landscape
Der Default-Header ist recht simpel. Man kann ihn mit Option --header=STRING umdefinieren oder einen sog. "Fancy Header" auswählen, der die Headerinformation fix-und-fertig vorgibt und die Seite zusätzlich durch Umrandungen und Trennlinen gestaltet. Welche Fancy Header zur Verfügung stehen, ist auf der man page nicht dokumentiert, kann aber anhand der Fancy-Header-Definitionsdateien ermittelt werden:
$ ls -l /usr/share/enscript/*.hdr
Mir erscheint Fancy Header edd am zweckmäßigsten:
--fancy-header=edd
Beim Fancy Header edd steht im Kopf der Seite sämtliche relevante Information:
Außerdem werden die beiden Spalten des zweiseitigen Drucks durch eine senkrechte Linie optisch getrennt.
Programm-Quelltext ist leichter lesbar, wenn Schlüsselworter und andere Sprachbestandteile hervorgehoben werden. Bei Angabe der Option --highlight führt enscript ein Syntax-Highlighting durch:
--highlight=LANGUAGE
Die Liste der unterstützen Sprachen erhält man mit
$ enscript --help-highlight
Leider beherrscht enscript kein UTF-8. Im Falle einer UTF-8-Datei müssen wir in ein Encoding wandeln, mit dem enscript umgehen kann. Das Default-Encoding von enscript ist latin1. Enthält unsere UTF-8-Quelltext-Datei FILE lediglich Umlaute und andere Zeichen, die in latin1 enthalten sind, brauchen wir bei enscript nichts weiter einstellen. Für die Wandlung von UTF-8 nach latin1 schalten wir iconv davor:
$ iconv -f utf-8 -t latin1 FILE | enscript ...
Die oben beschrieben Anforderungen sind bereits zu umfangreich, als dass sie mit jedem Ausdruck manuell angewendet werden könnten. Folgendes Bash-Script kapselt sie. Die Zeichensatz-Konvertierung ist hier mittels einer temporären Datei (statt einer Pipe) gelöst, damit enscript den Dateinamen und den letzten Änderungszeitpunkt erfährt.
| 1 | #!/bin/bash |
| 2 | |
| 3 | # NAME |
| 4 | # src-to-pdf - Quelltext nach PDF |
| 5 | # |
| 6 | # USAGE |
| 7 | # src-to-pdf LANGUAGE ENCODING SOURCE_FILE PDF_FILE |
| 8 | # |
| 9 | # DESCRIPTION |
| 10 | # Erzeuge zu Quelltext-Datei SOURCE_FILE mit Character-Encoding ENCODING |
| 11 | # in Programmiersprache LANGUAGE die (druckbare) PDF-Datei PDF_FILE. |
| 12 | # |
| 13 | # AUTHOR |
| 14 | # Frank Seitz, http://fseitz.de/ |
| 15 | |
| 16 | set -e |
| 17 | |
| 18 | if [ $# != 4 ]; then |
| 19 | PROG=`basename $0` |
| 20 | echo "Usage: $PROG LANGUAGE ENCODING SOURCE_FILE PDF_FILE" |
| 21 | exit 10 |
| 22 | fi |
| 23 | |
| 24 | LANG=$1 |
| 25 | ENC=$2 |
| 26 | IN=$3 |
| 27 | OUT=$4 |
| 28 | |
| 29 | FILE=`basename $IN` |
| 30 | TMPDIR=/tmp/enscript |
| 31 | TMPFILE=$TMPDIR/$FILE |
| 32 | |
| 33 | mkdir -p $TMPDIR |
| 34 | iconv -f $ENC -t latin1 $IN >$TMPFILE |
| 35 | touch --reference=$IN $TMPFILE |
| 36 | (cd $TMPDIR; enscript --quiet --output=- --columns=2 --landscape \ |
| 37 | --fancy-header=edd --lines-per-page=60 --highlight=$LANG $FILE) \ |
| 38 | | ps2pdf - $OUT |
| 39 | rm -rf $TMPDIR |
| 40 | |
| 41 | # eof |
Für systemglobale Anpassungen sollte man die ergänzende Datei /etc/enscriptsite.cfg anlegen. Vorteil: Es entstehen keine Konflikte, wenn durch die Paketverwaltung an der eigentlichen Configdatei /etc/enscript.cfg Änderungen vorgenommen werden. Hier meine systemglobalen Anpassungen:
# Site-spezifische Einstellungen DefaultFancyHeader: edd DefaultMedia: A4dj DefaultOutputMethod: stdout # eof
![]()
Mitunter möchte man einen Text oder ein Muster global über mehreren Dateien FILE ... ersetzen. Unter Unix/Linux geht das am einfachsten mit sed (GNU):
$ sed -i s/PATTERN/REPLACEMENT/g FILE ...
Das Gleiche, angewendet auf einen Dateibaum DIR:
$ find DIR -type f | xargs sed -i s/PATTERN/REPLACEMENT/g
Perl bietet die sed-Funktionaltät mit einer ähnlich einfachen Kommandozeile:
$ perl -pi -e s/PATTERN/REPLACEMENT/g FILE ...
Der Vorteil von Perl gegenüber sed ist dessen leistungsfähigere Regex-Engine. Bei GNU sed lassen sich mit Option -r "Extended Regular Expressions" einschalten (die eher an Perl Regexes heranreichen).
WICHTIG: Die Ersetzungsoperation wird zeilenweise angewendet, d.h. eine Ersetzung über Zeilengrenzen hinweg ist nicht möglich.
![]()
Wer wissen möchte, ob jüngst durchgeführte Änderungen an DNS-Einträgen in anderen Teilen der Welt bereits angekommen sind, kann sich des "DNS Propagation Checkers" whatsmydns.net bedienen.
Dieser fragt DNS-Server in verschiedenen Teilen der Welt ab, zeigt die Ergebnisse in Form einer Tabelle an und zeichnet sie in eine Weltkarte ein. Als Suchkriterium gibt man die Domain, den Record-Typ und - optional - den erwarteten Record-Wert vor.
Insbesondere nach dem Anlegen einer neuen Domain kann es eine Weile dauern bis die Nameserver-Definitionen global propagiert sind. Mit diesem Service lässt sich das verfolgen.
![]()
Bei der Auswertung von HTTP-Zugriffen möchte man u.U. die IP-Adressen zu Hostnamen auflösen. Das geht in Perl so:
| 1 | use Socket; |
| 2 | $hostname = gethostbyaddr(inet_aton($ip),AF_INET); |
Zwei Punkte sollte man dabei im Hinterkopf behalten:
nicht jede IP-Adresse kann zu einem Hostnamen aufgelöst werden (gethostbyaddr() liefert dann undef)
der Aufruf kann u.U. eine Weile dauern (bei mir bis zu 10 Sekunden)
![]()
Der schon etwas in die Jahre gekommene, aber für Webanwendungen immer noch hervorragende persistente Perl-Interpreter speedy kompiliert unter neueren Perl-Versionen nicht mehr.
Der Versuch endet mit dem Fehler:
speedy_perl.c: In function ?find_scr?:
speedy_perl.c:258:24: error: expected expression before ?SpeedyScript?
speedy_new(retval, 1, SpeedyScript);
^
../src/speedy_backend_main.h:41:39: note: in definition of macro ?speedy_new?
#define speedy_new(s,n,t) New(123,s,n,t)
Ursache ist, dass das C-Makro New() aus dem Perl-CORE (CORE/handy.h), nicht mehr existiert. Dies ist offenbar seit Perl 5.10 der Fall.
Die Lösung ist, anstelle des Makros New() das Makro Newx() zu benutzen. Hierzu muss in src/speedy_backend_main.h
#define speedy_new(s,n,t) New(123,s,n,t)
durch
#define speedy_new(s,n,t) Newx(s,n,t)
ersetzt werden.
Dann kompilieren die Quellen fehlerfrei. Getestet unter Perl 5.20.2.
Ein weiteres Problem tritt bei Perl 5.22.1 (mit gcc 5.3.1) auf:
In file included from ../src/speedy_inc.h:90:0,
from speedy.h:2,
from speedy_backend_main.c:24:
../src/speedy_file.h:54:19: warning: inline function
?speedy_file_set_state? declared but never defined
SPEEDY_INLINE int speedy_file_set_state(int new_state);
^
Dies lässt sich dadurch beheben, dass in src/speedy_inc.h die Macro-Definition SPEEDY_INLINE geändert wird zu
#ifdef __GNUC__ #define SPEEDY_INLINE /* __inline__ */ #else #define SPEEDY_INLINE #endif
Zum Testen (Perl 5.28.1) muss entgegen dem üblichen make test im Wurzelverzeichnis erst in das Unterverzeichnis speedy gewechselt werden:
$ cd speedy $ make test
![]()
Möchte man Text auf einen beliebigen einfarbigen Hintergrund setzen, muss man entscheiden, ob die Farbe des Hintergrunds eher hell oder dunkel ist, so dass man die Schriftfarbe geeignet wählen kann. Für einen dunklen Hintergrund sollte man eine helle Schrift (z.B. weiß) wählen und für einen hellen Hintergrund eine dunkle Schrift (z.B. schwarz), damit der Text problemlos lesbar ist.
Eine Heuristik, nach der dies für Farben des RGB-Farbraums entschieden werden kann, ist:
![]()
Die drei Koeffizienten 0.299, 0.587 und 0.114 gewichten die drei Farbkomponenten hinsichtlich der menschlichen Helligkeitswahrnehmung. Denn bei gleichem Farbwert wird Blau vom Menschen dunkler wahrgenommen als Rot und Rot dunkler als Grün. Die Summe der drei Koeffizienten ergibt 1, entsprechend hat die Funktion den gleichen Wertebereich wie die drei Farbkomponenten. Der übliche Wertebereich ist 0 bis 255. Bei einem Wert < 128 kann man die Farbe als dunkel ansehen, andernfalls als hell. Man kann die Funktion auch anwenden, um RGB-Farben in Grauwerte umzurechnen.
Perl:
$brightness = sqrt 0.299*$r**2 + 0.587*$g**2 + 0.114*$b**2;
JavaScript:
brightness = Math.sqrt(0.299*pow(r,2) + 0.587*pow(g,2) + 0.114*pow(b,2))
Hier ein Farbauswahl-Menü, dessen Einträge unter Verwendung der Helligkeitsfunktion generiert wurden, erkennbar daran, dass die Schrift auf der jeweiligen Hintergrundfarbe mal schwarz und mal weiß ist:
Der Artikel, der die Heuristik und ihren Ursprung genauer beschreibt: http://alienryderflex.com/hsp.html.
![]()
Overlays sind Bilder, die von Google Earth auf einen Bereich der Erdoberfläche (GroundOverlays) oder statisch ins Anwendungsfenster (ScreenOverlays) projiziert werden.
Zu den Bildern gehört eine Spezifikation in KML (Keyhole Markup Language), die die Bilder beschreibt und festlegt, wie Google Earth mit ihnen verfahren soll. KML ist XML-basiert und wird in einer Datei mit der Extension .kml gespeichert.
Die kml-Datei und die Bild-Dateien können zusammen in Form einer einzelnen kmz-Datei an Google Earth übergeben werden. Die kmz-Datei ist eine ZIP-Datei, die die genannten Dateien enthält.
Die kmz-Datei wird entweder über "File/Open" geladen oder als Parameter beim Aufruf von Google Earth angegeben.
| 1 | <?xml version="1.0" encoding="UTF-8"?> |
| 2 | <kml xmlns="http://www.opengis.net/kml/2.2"> |
| 3 | <Document> |
| 4 | <name>__NAME__</name> |
| 5 | <open>1</open> |
| 6 | <description>__DESCRIPTION__</description> |
| 7 | <GroundOverlay> |
| 8 | <name>Image</name> |
| 9 | <Icon> |
| 10 | <href>__FILE__</href> |
| 11 | </Icon> |
| 12 | <LatLonBox> |
| 13 | <north>__NORTH__</north> |
| 14 | <south>__SOUTH__</south> |
| 15 | <east>__EAST__</east> |
| 16 | <west>__WEST__</west> |
| 17 | </LatLonBox> |
| 18 | </GroundOverlay> |
| 19 | <ScreenOverlay> |
| 20 | <name>Legend</name> |
| 21 | <Icon> |
| 22 | <href>__LEGEND_FILE__</href> |
| 23 | </Icon> |
| 24 | <overlayXY x="0.02" y="0.98" xunits="fraction" yunits="fraction"/> |
| 25 | <screenXY x="0.02" y="0.98" xunits="fraction" yunits="fraction"/> |
| 26 | <size x="-1" y="-1" xunits="pixels" yunits="pixels"/> |
| 27 | </ScreenOverlay> |
| 28 | </Document> |
| 29 | </kml> |
Obige KML-Spezifiktion beschreibt ein Bild, das auf die Erdoberfläche projiziert wird (Element GroundOverlay) und ein Bild, das statisch in der oberen linken Ecke des Fensters dargestellt wird (Element ScreenOverlay). Die beteiligten Hauptelemente sind: Document, GroundOverlay, ScreenOverlay.
Für die Platzhalter __NAME__, __DESCRIPTION__ usw. müssen konkrete Werte eingesetzt werden.
Bezeichnung des Orts (Google-Terminus: Place). Diese Bezeichnung erscheint auf der linken Seite im Fenster und kann direkt ausgewählt werden.
Beschreibung zum Ort.
Dateiname des Bildes, das auf die Erdoberfläche projiziert wird.
Quadrupel von dezimalen Gradzahlen, die die geografische Region definieren.
Dateiname des statischen Bildes (das wir hier als "Legende" bezeichnen).
Wird die kmz-Datei von einem HTTP-Server ausgeliefert, sollte dieser den MIME-Type kennen:
application/vnd.google-earth.kmz kmz
Im Browser kann Google-Earth als Helper-Applikation vereinbart werden. Dann wird Google Earth beim Eintreffen einer kmz-Datei automatisch gestartet und positioniert an den betreffenden Ort.
Die Angaben für den Browser sind:
| Mime-Type: | application/vnd.google-earth.kmz |
| Description: | Keyhole Markup Language Archive |
| Extension: | kmz |
![]()
$ gpg --encrypt --recipient UID --batch --yes FILE --encrypt : Verschlüsselung --recipient UID : ID des Users, für den die Datei verschlüsselt wird --batch --yes : überschreibe Zieldatei FILE.gpg ohne Rückfrage, falls sie existiert
$ gpg --decrypt FILE.gpg >FILE --decrypt : Entschlüsselung
Das Erzeugen eines Schlüssels mit
$ gpg --gen-key
stoppt mit der Meldung
Not enough random bytes available. Please do some other work to give the OS a chance to collect more entropy! (Need <N> more bytes)
Entropie abfragen:
$ cat /proc/sys/kernel/random/entropy_avail
Folgende "Lösung", die im Netz viel genannt wird, sollte man nicht anwenden:
# apt-get install rng-tools # rngd -r /dev/urandom
Siehe Diskussion zur Entropieerhöhung. Geeignet ist dagegen das Forcieren von Plattenaktivität:
$ find / >/dev/null
Das Kommando wird einfach parallel zu gpg --gen-key ausgeführt, bis der Schlüssel erzeugt ist.
$ gpg --list-keys
$ gpg --gen-revoke UID
Das erzeugte Zertifikat auf einem gesicherten Datenträger speichern und zusätzlich ausdrucken.
![]()
Das Aufsetzen einer CGI-Applikation ist kein Zauberwerk. Es führen allerdings viele Wege nach Rom und es kann leicht passieren, dass ein "from scratch" erstelltes Setup überkomplex und krautig wird. Es folgt - in vier Schritten - das Setup, mit dem ich beim Erstellen von CGI-Applikationen starte. Es ist aufgeräumt und beruht auf technisch sauberen Konzepten. Von diesem Ausgangspunkt aus lässt sich eine beliebig umfangreiche Applikation aufbauen, ohne später den am Anfang gesteckten Rahmen verlassen zu müssen.
Jede nicht-triviale Applikation sollte sich im Dateisystem auf drei Bereiche verteilen. Wir wählen nach moderner Unix-Konvention hierfür eine /opt-Struktur:
<application> ist der Name der Applikation.
/opt/<application>/ +-- ... +-- www/ +-- bin/index.cgi /etc/opt/<application>/ +-- ... +-- apache.conf /var/opt/<application>/ +-- ... +-- access.log +-- error.log
Erläuterung:
Das Subverzeichnis www/ ist das DocumentRoot-Verzeichnis der Applikation. Hier werden statische Inhalte abgelegt, die vom HTTP-Server direkt ausgeliefert werden. Es ist das einzige Verzeichnis, dessen Inhalt von außen zugegriffen werden kann.
Die Datei bin/index.cgi ist das CGI-Programm, das alle dynamischen Inhalte generiert. Es ist außerhalb von DocumentRoot installiert, damit der Programmcode - auch im Falle einer Fehlkonfiguration - nicht von außen eingesehen werden kann.
Die Datei apache.conf enthält die Apache-Konfiguration der Applikation (s.u. "Apache-Konfiguration"). Die Datei wird in das Konfigurationsverzeichnis des Apache-Servers gelinkt (s.u. "Kommandos"), da sie dort gebraucht wird.
Die applikationsspezifischen Logdateien access.log und error.log, die der HTTP-Server schreibt, liegen im Bereich der Bewegungsdaten.
Hier ein minimales CGI-Programm. Es gibt die IP-Adresse des Client aus.
#!/usr/bin/perl -T
use strict;
use warnings;
print <<"__HTTP__";
Content-Type: text/plain
$ENV{'REMOTE_ADDR'}
__HTTP__
# eof
Die Apache-Konfigurationsdatei vereinbart einen VirtualHost und zwei Verzeichnisse:
# Apache Config for <application> <VirtualHost *:80> ServerName [host].[domain] DocumentRoot /opt/[application]/www ScriptAlias /index.cgi /opt/[application]/bin/index.cgi RedirectMatch ^/$ /index.cgi ErrorLog /var/opt/[application]/error.log CustomLog /var/opt/[application]/access.log combined </VirtualHost> <Directory /opt/[application]/bin> Options ExecCGI Require all granted </Directory> <Directory /opt/[application]/www> Require all granted </Directory> # eof
Erläuterung:
Die Angaben [host], [domain] und [application] sind Platzhalter, die passend zur jeweiligen Applikation gesetzt werden müssen.
ServerName definiert die Domain, unter der die Applikation im Netz erreicht wird.
DokumentRoot definiert das Verzeichnis für statische Inhalte (HTML-, CSS-, JavaScript-, Bilddateien usw.)
SkriptAlias definiert das CGI-Programm für dynamische Inhalte. Als Name wird hier index.cgi vereinbart. Es kann auch anders heißen. Es wird aus dem bin-Verzeichnis heraus aufgerufen, das aus Sicherheitsgründen nicht unterhalb von DocumentRoot liegt.
RedirectMatch definiert die Umschreibungsregel, mit der der Client auf das CGI-Programm gelenkt wird, wenn kein Pfad angegeben ist. Die Regel lenkt also auf den Start-URL der Applikation.
ErrorLog und CustomLog definieren den Ort, an den die Server-Logdateien geschrieben werden, und - im Falle von CustomLog - zusätzlich das Format der Datei (combined).
Mit der Option ExecCGI wird dem Webserver gestattet, im Verzeichnis /opt/[application]/bin das CGI-Programm index.cgi auszuführen.
Mit Require all granted wird der Außenwelt bedingungsloser Zugriff auf die beiden Verzeichnisse /opt/[application]/bin und /opt/[application]/www eingeräumt.
Mit folgenden Kommandos wird das oben beschriebene Apache-Setup im Webserver aktiviert. Hierfür sind root-Rechte erforderlich.
1 - Apache-Konfiguration der Applikation verlinken (Debian):
# ln -s /etc/<application>/apache.conf /etc/apache2/sites-available/<application>.conf
2 - Apache-Konfiguration der Applikation aktivieren:
# a2ensite <application>
3 - Apache-Modul für CGI-Ausführung aktivieren:
# a2enmod cgid
4 - Apache-Setup in den laufenden Server übernehmen (Debian):
# service apache2 reload
Wird in die VirtualHost-Definition anstelle von
ScriptAlias /index.cgi /opt/<application>/bin/index.cgi RedirectMatch ^/$ /index.cgi
die Definition
RewriteEngine on RewriteRule ^/([A-Z0-9a-z/]+)$ /opt/<application>/bin/index.cgi/$1 [H=cgi-script] RedirectMatch ^/$ /<start>
eingesetzt, tritt das CGI-Programm im URL nicht mehr in Erscheinung. Zusätzlich werden alle Pfade, die ausschließlich aus den Zeichen A-Z0-9a-z/ bestehen, via $PATH_INFO an das CGI-Programm übergeben.
Die RewriteEngine muss zuvor verfügbar gemacht werden mit:
# a2enmod rewrite
![]()
Mit der Direktive Redirect kann ein Seitenzugriff auf eine andere Seite umgeleitet werden. Die Umleitung schließt alle Subpfade ein, also Seiten mit gleichem Pfadanfang.
Möchte man ein Directory auf ein Subdirectory umleiten, klappt es mit Redirect nicht, da dies zu einer Endlos-Rekursion führt. Die Redirect-Regel
Redirect /a /a/b
führt bei Aufruf von /a zu der endlosen Kette von HTTP-Aufrufen
/a /a/b /a/b/b /a/b/b/b ...
bis der Browser dies erkennt und mit einer Meldung wie
Redirect Loop: Redirection limit for this URL exceeded.
abbricht.
Die Lösung liefert die (leistungsfähigere) Direktive RedirectMatch. Mit dieser lässt sich der umzulenkende Pfad per Regex präzise eingrenzen:
RedirectMatch /a$ /a/b
Das Dollarzeichen verankert den Pfad /a am Ende des URL, so dass Subpfade nicht mehr matchen und die Rekursion unterbleibt.
Da durch die Regel keine Subpfade weitergeleitet werden, müssen die Zugriffe innerhalb von /a/b relativ sein.
Ist das Ausgangsdirectory das Root-Directory, muss auch der Anfang verankert werden, da jedes Verzeichnis auf / endet:
RedirectMatch ^/$ /a
![]()
PostgreSQL gilt als das beste frei erhältliche Relationale Datenbanksystem. Es besitzt viele Gemeinsamkeiten mit Oracle, ist aber wesentlich leichter zu administrieren. Hier die wichtigsten Kommandos, um damit an den Start gehen zu können.
# apt-get install postgresql
# su - postgres
Nur von diesem Unix-Account aus kann nach der Installation eine Connection zum DBMS aufgebaut werden.
$ psql -l [Liste]
Nach der Installation existiert zunächst nur die Datenbank postgres.
$ createdb DB ... $ dropdb DB
$ psql postgres=# \du
oder
postgres=# SELECT rolname FROM pg_roles;
$ createuser USER ... $ dropuser USER
Bei Angabe der Option --superuser erhält der Benutzer Admin-Rechte:
$ createuser --superuser USER
Benutzer sind global für alle Datenbanken einer Installation. Zunächst existiert nur der Benutzer postgres. Soll der User USER von einem anderen Account als dem entsprechenden Unix-Account connecten können, muss ein Passwort vergeben werden. Option -P.
Ist ein DB-User erzeugt, kann dieser vom gleichnamigen Unix-Account oder per Passwort, falls eins vergeben wurde, von einem anderen Account per psql auf die Datenbank zugreifen.
USER$ psql DB psql (9.4.3) Type "help" for help. ... DB=#
Wurde ein Passwort für User USER vergeben, aber die Anmeldung von einem anderen Accout aus schlägt fehl mit der Meldung
$ psql -U USER DB psql: FATAL: Peer authentication failed for user "USER"
dann muss in pg_hba.conf die Authentisierungsmethode für lokale Logins geändert werden von
local all all peer
in
local all all md5
und anschließend der Server neu gestartet werden.
| Schemata: | \dn |
| Tabellen: | \dt |
| Views: | \dv |
| Sequenzen: | \ds |
Liste aller interaktiven psql-Kommandos: \?
| Alle Datenbanken: | pg_dumpall >FILE |
| Eine Datenbank: | pg_dump DB >FILE |
| Importieren: | psql -f FILE DB |
Die Zeitzone kann für eine Session abweichend gesetzt werden:
SET TIME ZONE 'Europe/Berlin';
Die Default-Zeitzone ist in postgresql.conf definiert:
timezone = 'Europe/Berlin'
Datumsangaben im Format YYYY-MM-DD:
SET datestyle TO iso, ymd;
Aktueller Zeitpunkt:
select localtimestamp(0);
liefert die Zeit entsprechend dem eingestellten Format
2015-06-09 11:44:29
Client arbeitet mit ISO-8859-1:
SET client_encoding TO iso88591
Client arbeitet mit UTF-8:
SET client_encoding TO utf8
Siehe: http://www.postgresql.org/docs/9.4/static/multibyte.html
Der clientseitige Zeichensatz kann jederzeit umgeschaltet werden. Wenn Daten mit unterschiedlichem Encoding verarbeitet werden, besteht die Möglichkeit, vor dem Schreiben auf die Datenbank das clientseitige Encoding umzuschalten. Die Konvertierung wird dann vom Server übernommen.
SET standard_conforming_strings TO on
Die folgenden Einträge ermöglichen den Zugriff von allen Hosts für alle User und alle Datenbanken.
In pg_hba.conf oberhalb der anderen Einträge hinzufügen:
# TYPE DATABASE USER CIDR-ADDRESS METHOD host all all 0.0.0.0/0 md5
In postgresql.conf eintragen:
listen_addresses = '*'
# /etc/init.d/postgresql-X.Y restart
Siehe Kapitel "Upgrading" in der Doku.
![]()
Jedes Kommandozeilenprogramm, das Texte und Meldungen mit Non-ASCII-Zeichen (z.B. Umlauten) aufs Terminal ausgibt, sollte die aktuelle Locale-Einstellung berücksichtigen, damit sichergestellt ist, dass alle Zeichen richtig dargestellt werden.
Es reicht nicht aus, dass die Ausgabe unter der eigenen Terminal-Einstellung (z.B LANG=xx_XX.UTF-8) korrekt aussieht. Denn hat der Anwender ein abweichendes Character-Encoding konfiguriert (z.B. LANG=xx_XX.ISO-8859-1), sieht er anstelle der Non-ASCII-Zeichen Zeichensalat, wenn das Programm nicht explizit in dieses Encoding wandelt (in diesem Fall sähe er zwei Zeichen statt einem für jeden Umlaut).
In Perl lässt sich diese nicht-triviale Aufgabe elegant durch Verwendung des Pragma open in Verbindung mit der Angabe ':locale' lösen. Die Zeile
use open OUT=>':locale';
am Anfang des Programms sorgt dafür, dass für alle Ausgabeströme (einschl. STDOUT und STDERR) ein I/O-Layer eingerichtet wird, der die geschriebenen Daten automatisch gemäß dem in der Umgebung eingestellten Character-Encoding enkodiert.
Beispiel: Die folgenden beiden Programme geben für beliebig in der Umgebung eingestellte Zeichensätze mit deutschen Umlauten - u.a. UTF-8 und ISO-8859-1 - zwei Zeilen mit Umlauten aus, die korrekt dargestellt sein sollten. Hierbei erzeugt print die Ausgabe via STDOUT und warn die Ausgabe via STDERR.
Quelle mit einem Latin1-Editor erstellt:
#!/usr/bin/env perl
use strict;
use warnings;
use open OUT=>':locale';
my $str = "ÄÖÜäöüß";
print "$str\n";
warn "$str\n";
# eof .
Quelle mit einem UTF-8-Editor erstellt:
#!/usr/bin/env perl
use strict;
use warnings;
use utf8; # <- UTF-8 Quelltext
use open OUT=>':locale';
my $str = "ÄÖÜäöüß";
print "$str\n";
warn "$str\n";
# eof .
![]()
Die Briefklasse scrlttr2 ist die vermutlich leistungsfähigste LaTeX-Klasse zum Setzen von (DIN-)Briefen. Sie hat aus meiner Sicht jedoch den kleinen Fehler, dass sie dem Briefkörper eine andere Breite zuweist als dem Briefkopf. Der Briefkörper ist schmaler und unter dem Briefkopf zentiert, was die Lesbarkeit erhöhen soll. Dadurch wirkt der Brieftext gegenüber dem Adressfeld jedoch verschoben. Gerade bei kürzeren Briefen sieht das nach meinem Empfinden nicht gut aus.
Scrlttr2 bietet leider keine einfache Möglichkeit, das Layout so umzustellen, dass die Ränder des Briefkörpers mit dem Adressfeld und der Kopfzeile abschließen.
Ich musste eine Weile suchen und herumexperimentieren, bis ich eine Lösung gefunden habe:
% Briefkörper bündig am Briefkopf ausrichten
\setlength{\oddsidemargin}{\useplength{toaddrhpos}}
\addtolength{\oddsidemargin}{-1in}
\setlength{\textwidth}{\useplength{firstheadwidth}}
Die ersten beiden Anweisungen setzen den linken Rand des Briefkörpers mit dem linken Rand des Adressfeldes gleich. Sie finden sich im Buch der Autors von KOMA-Script in Anhang E. Die dritte Anweisung macht den Briefkörper so breit wie den Briefkopf. Diese Anweisung habe ich ergänzt. Beides zusammen ergibt das angestrebte Layout.
Vorher/Nachher am Beispiel einer Rechnung:

Spezielle Anpassungen nach Installation von Debian Testing mit Xfce Desktop.
Beim ersten Login werden verschiedene Standardverzeichnisse im Home-Verzeichnis des Benutzers angelegt:
Desktop Documents Downloads Music Pictures Public Templates Videos
Die Pfade dieser Verzeichnisse können benutzerspezifisch in der Datei ~/.config/user-dirs.dirs umdefiniert werden. Eine globale Umdefinition ist in /etc/xdg/user-dirs.defaults möglich. Siehe auch keyboard(1).
Unter Debian wird diese Einstellung in der Datei /etc/default/keyboard vorgenommen. Die Konfiguration gilt sowohl für die Console als auch unter X11.
XKBMODEL="pc105" XKBLAYOUT="de" XKBVARIANT="nodeadkeys" <-- schaltet Dead Keys ab XKBOPTIONS="caps:none" <-- schaltet Caps Lock ab BACKSPACE="guess"
In /usr/share/X11/xkb/rules/xorg.lst sind alle Einstellmöglichkeiten (model, layout, variant, option) aufgezählt.
Settings / Appearance / Settings / Enable event sounds
Thunderbird: Preferences / General / Play a sound
Soundfiles unter: /usr/share/sounds
Pulse Audio Volume Control: Playback / System Sounds hochdrehen
Exim4 so konfigurieren, dass sämtliche Mail an einen Smarthost delegiert wird, mit:
# dpkg-reconfigure exim4-config
Option auswhlen: "mail sent by smarthost; no local mail"
Das Programm schreibt am Ende die Konfigurationsinformation in die Datei /etc/exim4/update-exim4.conf.conf.
Die Authentisierung auf dem Smarthost wird in die Datei /etc/exim4/passwd.client eingetragen. Hat der Server keine TLS-Verschlüsselung wird die Macro-Definition
AUTH_CLIENT_ALLOW_NOTLS_PASSWORDS='yes'
zur Datei /etc/exim4/update-exim4.conf.conf hinzugefügt.
Emacs-Tastaturkommandos sind auf den Eingabefeldern der GUI-Applikationen verfügbar, wenn als globale Einstellung vorgenommen wird:
Applications / Settings / Settings Editor / xsettings / Gtk / KeyThemeName / Edit / Value=Emacs
Das Flash-Plugin für den Mozilla-Abkömmling Iceweasel kann bei Adobe heruntergeladen werden: https://get.adobe.com/flashplayer/.
Installation: die .tar.gz Datei lokal entpacken und die darin enthaltene Shared Libraray ins Plugin-Verzeichnis des Browsers kopieren.
# cp libflashplayer.so /usr/lib/mozilla/plugins
Unter Add Ons / Plugins kann das Plugin im laufenden Browser aktiviert werden. Andernfalls wird es ab dem nächsten Neustart des Browsers genutzt.
Das Kernel-Modul für den Intel WLAN-Adapter (meines Rechners) ist proprietär und wird daher bei der Debian-Installation nicht automatisch mit installiert. Er ist jedoch im non-free Bereich verüfgbar und kann einfach nachinstalliert werden (vorausgesetzt, dass in /etc/apt/sources.list der Bereich non-free eingetragen ist):
# apt-get install firmware-iwlwifi
Dasselbe wie für den WLAN-Adapter gilt für die Ethernetkarte. Das Fehlen des Moduls rtl8411-2.fw wird beim Booten bemängelt, es scheint jedoch nicht wirklich benötigt zu werden, da das Ethernet-Interface auch ohne das Modul funktioniert. Gegen die Fehlermeldung hilft:
# apt-get install firmware-realtek
Xfce hat keinen eigenen Netzwerkmanager für die Verwaltung von LAN- und WLAN-Verbindungen. Ein leichtgewichtiger Netzwerkmanager ist Wicd.
Installation:
# apt-get install wicd
Er installiert sich als Autostart-Applikation und wird aus dem Panel oder unter Applications / Internet / Wicd Network Manager aufgerufen.
Beim Start sucht wicd nach den WLAN-Netzen der Umgebung. Führt dies zu der Meldung "No wireless networks found", ist möglicherweise das Wireless Interface (meist wlan0) nicht unter den Preferences eingetragen. Das Menü zum Aufruf des Dialogs verbirgt sich hinter dem Pfeil oben rechts.
2016-08-14
Debian-Paket (skypeforlinux-64-alpha.deb) von skype.com herunterladen (Link siehe https://wiki.debian.org/skype). Installation:
# apt-get update # gdebi skypeforlinux-64-alpha.deb
2015-05-23
Installation (32-Bit-Programm auf 64-Bit-System):
# dpkg --add-architecture i386 # apt-get update # wget -O skype-install.deb http://www.skype.com/go/getskype-linux-deb # dpkg -i skype-install.deb # apt-get -f install
Siehe: https://wiki.debian.org/skype
Per Default ist ein einfacher vi-Klon installiert, der im Insert-Mode die Escape-Sequenzen der Pfeiltasten nicht behandelt. Vim hat dieses Problem nicht:
# apt-get install vim
Ferner lohnt es sich, in die Vim-Konfigurationsdatei /etc/vim/vimrc zu schauen und dort weitere Optionen zu aktivieren, z.B. Mausunterstützung und Syntax-Highlighting.
Die Bell unterliegt nicht den Soundeinstellungen und ist extrem laut. Mit
$ xset b off
lässt sie sich abschalten. Soll das immer gelten, kann das Kommando unter Applications / Settings / Session and Startup / Application Autostart / Add zu den Autostart-Kommandos hinzugefügt werden.
Quelle definieren:
# vi /etc/apt/sources.list.d/webupd8team-java.list deb http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main deb-src http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main
Installation:
# apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys EEA14886 # apt-get update # apt-get install oracle-java8-installer
Version prüfen:
# java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
Installation:
# apt-get install bumblebee bumblebee-nvidia # shutdown -r now
Grafikanwendung starten:
$ optirun CMD
Status der Nvidia-Karte prüfen:
# cat /proc/acpi/bbswitch
Weitere Infos:
![]()
Um einen Unix Epoch-Wert (Sekunden seit 1.1.1970 0 Uhr UTC) mit Shell-Mitteln in eine lesbare Zeitangabe (lokale Zeitzone) zu wandeln, kann man sich des Kommandos date bedienen:
$ date -d @1406546442 Mo 28. Jul 13:20:42 CEST 2014
Dasselbe in einer besser strukturierten Darstellung:
$ date -d @1406546442 '+%F %T %z' 2014-07-28 13:20:42 +0200
Hierbei ist:
%F - Datum %T - Uhrzeit %z - Zeitzone als hhmm-Offset
Soll die Ausgabe in einer anderen als der lokalen Zeitzone erfolgen, wird die Environment-Variable TZ entsprechend gesetzt (hier Ausgabe in UTC):
$ TZ=UTC date -d @1406546442 '+%F %T %z' 2014-07-28 11:20:42 +0000
Dasselbe im ISO-8601 Datumsformat (sekundengenau):
$ date -d @1406546442 --iso-8601=seconds 2014-07-28T13:20:42+0200
Die Umkehrung - also die Wandlung einer lesbaren Zeitangabe (der lokalen Zeitzone, wenn keine angegeben ist, hier: MESZ) in Epoch - ist auch möglich:
$ date -d '2014-07-28 13:20:42' +%s 1406546442
Soll die Interpretation in einer anderen Zeitzone als der lokalen Zeitzone erfolgen, kann dies durch Setzen der Environmentvariable TZ erreicht werden:
$ TZ=UTC date -d '2014-07-28 13:20:42' +%s 1406553642 # Differenz zu oben: -7200, also minus 2 Stunden gegenüber MESZ
Der aktuelle Zeitpunkt als Epoch-Wert:
$ date +%s 1406548003
Details siehe date(1) Manpage
![]()
Um Datei-Dubletten in einem Verzeichnis oder Dateibaum zu finden, gibt es unter Unix/Linux meines Wissens keine Standard-Toolchain. Es existiert aber eine Programmsammlung namens fslint, die u.a. auch ein Programm zum Finden von Dubletten enthält.
Installation (Debian):
# apt-get install fslint
Ungewöhnlich an dieser Programmsammlung ist, dass die enthaltenen Kommandozeilenprogramme nicht in ein Verzeichnis des Suchpfads installiert werden, sondern zunächst nur über das GUI-Programm fslint-gui genutzt werden können. Die Kommandozeilenprogramme werden von der Shell erst gefunden, wenn man PATH um den Installationspfad der Werkzeugsammlung erweitert:
$ PATH=/usr/share/fslint/fslint:$PATH
Auch existieren zu den einzelnen Programmen - außer dem GUI-Programm - keine Manpages. Informationen über die Benutzung erhält man bei Aufruf des jeweiligen Programms mit der Option -h.
Eine Übersicht über die Programmsammlung:
$ man fslint-gui
Das Programm zum Finden von Dubletten heißt findup.
Beschreibung des Programms und Beispiele:
$ findup -h
Finde alle Dubletten in Dateibaum DIR (also rekursiv) und zeige diese an:
$ findup DIR
Lösche alle Dubletten in Dateibaum DIR - bis auf jeweils ein Exemplar:
$ findup -d DIR
Bei Angabe der Option -r werden Subverzeichnisse nicht durchsucht.
Links:
![]()
Wer sichergehen will, dass der selbstgemachte Videoclip wegen der Hintergrundmusik von YouTube nicht gesperrt oder mit Werbung für die Musik versehen wird, kann versuchen, die Audio-Daten so zu verändern, dass die YouTube Content-Erkennung nicht anspricht.
Ein Weg, dies zu erreichen, ist, die Tonhöhe des Audio-Materials zu verändern. Eine Änderung um ein, zwei oder mehr Halbtöne ist hierfür notwendig. Eventuell muss mit verschiedenen Werten experimentiert werden. Nachteile: Die Audio-Manipulation ist hörbar und sie hat Auswirkungen auf das Timing innerhalb des Clip, weswegen man die Änderung vorab machen und austesten sollte (s.u.).
In audacity findet sich die Programmfunktion zum Ändern der Tonhöhe unter dem Menüpunkt Effect/Change Pitch. Ein positiver Wert im Eingabefeld Semitones hebt die Tonhöhe an, ein negativer Wert reduziert sie - jeweils um die angegebene Anzahl Halbtonschritte.
Mit avconv (oder ffmpeg) lässt sich aus einem einzelnen Bild und der veränderten Audio-Datei ein Videoclip erzeugen, der testweise nach YouTube hochgeladen werden kann.
$ avconv -loop 1 -i IMAGE -i AUDIO -t S ... VIDEO.mp4 -loop 1 : verwende die nachfolgende Bilddatei für jeden Frame -i IMAGE : eine beliebige Bilddatei, z.B. in der Größe 640x360 Pixel -i AUDIO : die veränderte Audio-Datei -t S : Länge des generierten Clip in Sekunden, z.B. 60 für eine Minute VIDEO.mp4 : generierter Test-Clip für YouTube
![]()
Mitunter weiß (oder vermutet) man, dass ein Programm Dateien in einen Bereich des Dateisystems schreibt, aber man weiß nicht genau in welche Verzeichnisse und wie die Dateien heißen.
Dem lässt sich auf den Grund gehen, indem man sich unmittelbar nach Beendigung des Programms die Pfade des betreffenden Dateibaums chronlogisch nach dem letzten Modifikationszeitpunkt sortiert anzeigen lässt. Unter den letzten Pfaden in der Liste sollten die gesuchten Dateien zu finden sein.
Die Unix-Kommandozeile (mit GNU find), die dies leistet, lautet:
$ find DIR -type f -printf '%T+ %p\n' | sort
Hierbei ist DIR das Wurzelverzeichnis des untersuchten Dateibaums. Für jede Datei wird eine Zeile ausgegeben, bestehend aus der mtime in ISO-ähnlicher Darstellung (%T+) und dem Pfad (%p) der Datei.
Details siehe find(1) Manpage
![]()
$ convert INPUT_FILE -resize WIDTHxHEIGHT OUTPUT_FILE
oder "in place", anwendbar auf mehrere Dateien
$ mogrify -resize WIDTHxHEIGHT FILE ...
Vertikal (links-nach-rechts):
$ convert INPUT_FILE -flop OUTPUT_FILE
Horizontal (oben-nach-unten):
$ convert INPUT_FILE -flip OUTPUT_FILE
$ gimp FILE
Layer / Transparency / Add Alpha Channel
Tools / Selection Tools / By Color Select
Im Bild: Klick auf die Hintergrundfarbe
Edit / Cut
File / Export As... (z.B. als PNG)
$ convert INPUT_FIILE -background COLOR -flatten OUTPUT_FILE
Sonderfall weiss (da Default für -background):
$ convert INPUT_FIILE -flatten OUTPUT_FILE
$ exiftool -all= INPUT_FILE ...
Bei diesem Kommando kann eine Liste von Bilddatein angegeben werden. Die resultierenden Bilddateien werden unter dem Namen des Originals gespeichert, während die jeweilige Originaldatei mit dem Suffix _original gesichert wird.
Bei Angabe der Option -overwrite_original werden die Originaldateien nicht gesichert:
$ exiftool -all= -overwrite_original INPUT_FILE ...
$ convert INPUT_FILE -crop WIDTHxHEIGHT+XOFFS+YOFFS OUTPUT_FILE
WIDTHxHEIGHT ist die Geometrie des erzeugten Bildes und XOFFS und YOFFS sind der x- und y-Offset bezogen auf die Geometrie des Ausgangsbildes.
Wert von -crop bei Wandlung von 16:9 nach 4:3:
| 16:9 | 4:3 | -crop (mittig) | XOFFS Bereich |
|---|---|---|---|
| 1920x1080 | 1440x1080 | 1440x1080+240+0 | 0 .. 480 |
| 1280x720 | 960x720 | 960x720+160+0 | 0 .. 320 |
WIDTH = HEIGHT / 3 * 4
1920x1080:
$ convert INPUT_FILE -resize 1920x1440 -crop 1920x1080+0+180 OUTPUT_FILE
Bereich YOFFS: 0 .. 360
1280x720:
$ convert INPUT_FILE -resize 1280x960 -crop 1280x720+0+120 OUTPUT_FILE
Bereich YOFFS: 0 .. 240
HEIGHT = WIDTH / 16 * 9
ImageMagick (allgemeine Bildbearbeitung)
exiftool (Bearbeitung der Metainformation)
![]()
Mitunter stößt man - insbesondere auf YouTube - auf Videos, die im falschen Seitenverhältnis produziert wurden. Dies macht sich dadurch bemerkbar, dass der Inhalt verzerrt, z.B. horizontal gestaucht ist (bei Seitenverhältnis 4:3 statt 16:9). Dies lässt sich mit avconv/ffmpeg korrigieren.
Hierzu genügt es jedoch nicht, das Video mit -vf scale=WIDTH:HeiGHT zu reskalieren, da dies bei einem abweichenden WIDTH:HEIGHT-Verhältnis zu schwarzen Balken oben/unten oder rechts/links führt. Denn das ursprüngliche Seitenverhältnis des Video wird beibehalten und der durch die Skalierung entstehende Leerraum wird schwarz aufgefüllt.
Dieser meist unerwünschte Effekt findet nicht statt, wenn zusätzlich das Seitenverhältnis (engl. aspect ratio) definiert wird. Die betreffende avconv/ffmpeg-Option lautet -aspect ASPECT.
Kommandozeile:
$ avconv -i INFILE -vf scale=WIDTH:HEIGHT -aspect ASPECT ... OUTFILE -vf scale=WIDTH:HEIGHT : Breite/Höhe des Video gemäß neuem Seitenverhältnis -aspect ASPECT : neues Seitenverhältnis, z.B. 16:9 oder 4:3 (s.u.)
Doku zum Wert ASPECT auf der avconv(1) Manpage:
ASPECT can be a floating point number string, or a string of the form num:den, where num and den are the numerator and denominator of the aspect ratio. For example "4:3", "16:9", "1.3333", and "1.7777" are valid argument values.
![]()
Ein Multiuser Minecraft-Server ist ein einzelner Jar-File, der auf einem Host mit Java Runtime Environment gestartet wird und dann Client-Verbindungen auf Port 25565 entgegen nimmt.
Auf der Download-Seite https://minecraft.net/download von Mojang findet sich der Link zum Jar-File URL und das Kommando CMD, mit dem der Server gestartet wird.
Werte für URL und CMD zum Zeitpunkt des Schreibens dieses Texts:
URL: https://s3.amazonaws.com/Minecraft.Download/versions/1.8.1/minecraft_server.1.8.1.jar CMD: java -Xmx1024M -Xms1024M -jar minecraft_server.1.8.1.jar nogui
Die Installation auf Debian-basierten Linux-Systemen in Kurzform:
$ sudo apt-get install default-jre $ wget URL $ CMD $ vi eula.txt eula=true $ CMD
Java Runtime Environment installieren (falls noch nicht vorhanden)
$ sudo apt-get install default-jre
Jar-File des Minecraft-Servers herunterladen
$ wget URL
URL ist der Download-Link von der Mojang Download-Seite (s.o.).
Minecraft-Server starten
$ CMD
CMD ist das Kommando von der Mojang Download-Seite (s.o.).
Beim ersten Start erzeugt der Server im aktuellen Verzeichnis mehrere Dateien - u.a. eula.txt - und terminiert sofort (!) mit der Meldung "You need to agree to the EULA in order to run the server. Go to eula.txt for more info".
Minecraft End User Licence Agreement (EULA) akzeptieren
Die Zustimmung erteilt man, indem man in eula.txt die Variable eula von false auf true setzt.
$ vi eula.txt eula=true
Minecraft-Server noch einmal starten
Server noch einmal wie in Schritt 3 starten. Nun sollte er laufen. Am Shellprompt gestartet, schreibt er INFO-Meldungen aufs Terminal und läuft nun so lange, bis er gekillt wird.
Port-Freischaltung
Als letztes muss in der Firewall eine Port-Freischaltung/Weiterleitung für Port 25565 konfiguriert werden, damit der Minecraft-Server von außen erreicht werden kann. Dieser Schritt lässt sich nicht allgemeingültig beschreiben, da er von den Gegebenheiten des lokalen Netzwerks abhängt.
In meinem Fall ist der Host eine EC2-Instanz in der Amazon Cloud. Dort wird die Portfreigabe in der Security-Group der Instanz eingestellt. Durch Hinzufügen einer weiteren Regel ("Custom TCP Rule") bei den Eingangsverbindungen ("Inbound") mit Protocol=TCP, Port Range=25565 und Source=Anywhere (0.0.0.0/0) ist der Mincraft-Server weltweit erreichbar.
Admins werden in der Datei ops.json definiert. Die JSON-Datei enthält zunächst eine leere Liste [], definiert also keine Admins.
Für jeden Admin/Operator wird ein Eintrag zur Liste hinzugefügt. Aufbau der Datei:
[
{
"uuid": "UUID",
"name": "USERNAME",
"level": LEVEL
},
...
]
Hierbei ist:
Zeichenkette, die den Benutzer identifiziert. Diese Zeichenkette lässt sich z.B. auf http://mcuuid.net/ aus dem Benutzernamen erzeugen.
Der Benutzername.
Der Berechtigungs-Level. Vier Level werden unterschieden, von denen 4 den größten Umfang an Rechten besitzt:
Can bypass spawn protection.
Can use /clear, /difficulty, /effect, /gamemode, /gamerule, /give, /summon, /setblock and /tp and can edit command blocks.
Can use /ban, /deop, /kick, and /op.
Can use /stop.
Server.properties: http://minecraft.gamepedia.com/Server.properties
![]()
Anstelle eines URL können dem src-Attribut des <img>-Tag auch Bilddaten zugewiesen werden. Damit ist es möglich, Bilder direkt in HTML einzubetten. Die Syntax hierfür lautet:
<img src="data:image/TYPE;base64,DATA" .../>
Hierbei ist TYPE der Typ des Bildes (jpeg, png, gif, ...) und DATA sind die Base64-encodierten Bilddaten (s.u.).
Dies ist für dynamisch generierte HTML-Seiten mit dynamisch generierten Grafiken, wie z.B. Plots, nützlich. Die Grafiken können so mit dem umgebenden HTML zusammen erzeugt und in einer einzigen (HTML-)Datei ausgeliefert werden.
Unter Perl findet sich die Funktion für die Umwandlung von binären Daten nach Base64 im Core-Modul MIME::Base64:
use MIME::Base64 (); ... $data = MIME::Base64::encode_base64($image,'');
Die binären Bilddaten stehen hier auf $image. Der Leerstring als zweiter Parameter bewirkt, dass die Base64-Zeichenkette einzeilig erzeugt wird.
![]()
Installation von SVN auf Debian-basierten Systemen:
$ sudo apt-get install subversion
REPOSITORY und WORK sind im folgenden zwei beliebig gewählte lokale Verzeichnisse.
Leeres SVN-Repository REPOSITORY erzeugen:
$ mkdir REPOSITORY $ svnadmin create REPOSITORY
Leeres Repository in Arbeitsverzeichnis WORK auschecken:
$ svn checkout file://REPOSITORY WORK Checked out revision 0.
In WORK kann nun eine beliebige Substruktur aufgebaut werden.
Details siehe Version Control with Subversion
![]()
Kernel-Parameter können zur Laufzeit des Linux-Systems mit dem Kommando sysctl geändert werden.
Typischer Problemfall: Beim Starten meldet ein Programm (hier der PostgreSQL-Server), dass ein Kernel-Parameter (hier die maximale Größe eines Shared-Memory-Segments) nicht ausreicht:
The PostgreSQL server failed to start. FATAL: could not create shared memory segment. DETAIL: Failed system call was shmget(key=5432001, size=536084480, 03600). HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded your kernel's SHMMAX parameter.
Der betreffende Kernel-Parameter (hier kernel.shmmax) kann mit
$ sysctl kernel.shmmax kernel.shmmax = 33554432
abgefragt werden. Man sieht, der Wert ist zu klein. Mit
# sysctl kernel.shmmax=600000000 kernel.shmmax = 600000000
kann der Parameter auf einen ausreichenden Wert gesetzt werden. Zum Setzen muss man über root-Rechte verfügen. Anschließend sollte der Fehler nicht mehr auftreten.
Um die Setzung permanent zu machen, muss sie in eine der Konfigurationsdateien des Systems eingetragen werden, typischerweise /etc/sysctl.conf oder in eine selbst erstellte Datei in /etc/sysctl.d, z.B. /etc/sysctl.d/NN-local.conf (NN ist der numerische Wert, der die Postion in der Ladereihenfolge festlegt).
Eine selbst erstellte Datei hat den Vorteil, dass Änderungskonflikte vermieden werden, wenn die Paketverwaltung Änderungen an der globalen Datei /etc/sysctl.conf vornimmt.
![]()
Das Perl-Modul SOAP::WSDL stellt Mittel bereit, um Web Services ansprechen zu können, für die eine WSDL-Definition existiert.
Der bevorzugte Weg ist, aus der WSDL-Definition eine Client-Schnittstelle zu generieren und diese zur Interaktion mit dem Web-Service zu nutzen. Die generierte Schnittstelle ist objektorientiert, besteht also aus einer Sammlung von Klassen.
Die Schnittstelle wird von dem Programm wsdl2perl.pl generiert, das Bestandteil des Moduls SOAP::WSDL ist. Ein typischer Aufruf ist:
$ wsdl2perl.pl -b DIR -p PREFIX URL DIR : Zielverzeichnis (Default: ".") PREFIX : Präfix für alle generierten Klasse (Default: "My") URL : URL der WSDL-Definition
Der Web Service "Global Weather" ist ein einfacher Dienst, der aktuelle Wetterinformation über größere Städte der Welt liefert. Als Ausgangsinformation steht zur Verfügung:
eine verbale Beschreibung der SOAP-Schnittstelle: http://www.webservicex.net/globalweather.asmx
die WSDL-Definition der SOAP-Schnittstelle: http://www.webservicex.net/globalweather.asmx?wsdl
Aus der formalen WSDL-Definition generieren wir mittels wsdl2perl.pl eine objektorientierte Client-Schnittstelle für Perl:
$ wsdl2perl.pl -b lib -p GW:: http://www.webservicex.net/globalweather.asmx?wsdl Creating element class GW/Elements/GetWeather.pm Creating element class GW/Elements/GetWeatherResponse.pm Creating element class GW/Elements/GetCitiesByCountry.pm Creating element class GW/Elements/GetCitiesByCountryResponse.pm Creating element class GW/Elements/string.pm Creating typemap class GW/Typemaps/GlobalWeather.pm Creating interface class GW/Interfaces/GlobalWeather/GlobalWeatherSoap.pm
Nun können wir einen Client programmieren, der das Wetter abfragt:
#!/usr/bin/env perl
use strict;
use warnings;
use lib 'lib';
use GW::Interfaces::GlobalWeather::GlobalWeatherSoap;
if (@ARGV != 2) {
die "Usage: gw COUNTRY CITY\n";
}
my ($country,$city) = @ARGV;
my $soap = GW::Interfaces::GlobalWeather::GlobalWeatherSoap->new;
my $res = $soap->GetWeather({
CountryName=>$country,
CityName=>$city,
});
printf "%s\n",$res->get_GetWeatherResult;
Aufruf und Resultat:
$ gw germany hamburg <?xml version="1.0" encoding="utf-16"?> <CurrentWeather> <Location>Hamburg-Finkenwerder, Germany (EDHI) 53-32N 009-50E 13M</Location> <Time>Jun 22, 2013 - 09:20 AM EDT / 2013.06.22 1320 UTC</Time> <Wind> from the SSW (200 degrees) at 15 MPH (13 KT) (direction variable):0</Wind> <Visibility> greater than 7 mile(s):0</Visibility> <SkyConditions> mostly cloudy</SkyConditions> <Temperature> 69 F (21 C)</Temperature> <DewPoint> 57 F (14 C)</DewPoint> <RelativeHumidity> 64%</RelativeHumidity> <Pressure> 29.85 in. Hg (1011 hPa)</Pressure> <Status>Success</Status> </CurrentWeather>
![]()
Help -> Install New Software...
Add...
Name: EPIC, Location: http://e-p-i-c.sf.net/updates/testing
"EPIC Mail Components" auswählen und "Next >" betätigen
"EPIC" auswählen und "Next >" betätigen
Lizenzbedingungen akzeptieren und "Finish" betätigen
Window -> Preferences -> Perl EPIC -> Editor
Displayed tab width: 4 Insert tabs/spaces on indent: 1->4 [x] use spaces instead of tabs
Window -> Preferences -> Perl EPIC -> Editor
[x] Wrap lines
File -> New -> Project...
Perl Project
Window -> Preferences -> General -> Appearence -> Colors and Fonts
Doppelklick auf "Text Font". Dort die Fontgröße auswählen.
![]()
var img = new Image();
img.onload = function () {
// Bild existiert
};
img.onerror = function () {
// Bild existiert nicht
};
img.src = URL;
![]()
Zum Validieren von UTF-8 kann GNU iconv genutzt werden. Der Aufruf
$ iconv -f UTF-8 FILE >/dev/null
liefert Exitcode 0, wenn die Datei FILE valides UTF-8 enthält, andernfalls 1. Im Falle von nicht-validem UTF-8 schreibt iconv zusätzlich eine Fehlermeldung nach stderr:
iconv: illegal input sequence at position N
Hierbei ist N der Byte-Offset, an dem die (erste) ungültige Byte-Sequenz gefunden wurde.
![]()
Eine MySQL-Datenbank, die von innen (Host oder lokalem Netzwerk), jedoch nicht von außen (Internet) per TCP/IP erreichbar ist, kann von einem entfernten Rechner über einen SSH-Tunnel erreicht werden, wenn man einen SSH-Zugang zu dem Datenbank-Host oder einem Host des Netzwerks besitzt.
1 - SSH-Tunnel zum MySQL Port 3306 aufsetzen:
$ ssh <user>@<host> -L <port>:localhost:3306 -f -N -L <port>:localhost:3306 : Verbinde lokalen Port <port> remote mit MySQL Port 3306 -f : Lege den ssh-Prozess in den Hintergrund -N : Führe remote nichts aus (kein Login, kein Kommando)
2 - Mit der Datenbank verbinden:
$ mysql --host=localhost --port=<port> --protocol=tcp ...
oder
$ mysql --host=127.0.0.1 --port=<port> ...
Dieser spezielle Fall von SSH-Tunneling kann natürlich auch auf andere Dienste (Ports) übertragen werden.
Ein weiterer Artikel zu dem Thema: http://www.revsys.com/writings/quicktips/ssh-tunnel.html
Um mit einer lokalen phpMyAdmin-Applikation über den Tunnel auf die Remote-Datenbank zugreifen zu können, wird eine entsprechende Server-Definition in der phpMyAdmin-Konfiguration vereinbart, z.B. in /etc/phpmyadmin/conf.d/<Server-Name>.php:
<?php $cfg['Servers'][$i]['verbose'] = '<Server-Name>'; $cfg['Servers'][$i]['host'] = '127.0.0.1'; $cfg['Servers'][$i]['port'] = '3305'; $cfg['Servers'][$i]['connect_type'] = 'tcp'; $i++;
Das Timeout hochsetzen:
$cfg['LoginCookieValidity'] = <Wert in Sekunden>;
Z.B. ein Tag:
$cfg['LoginCookieValidity'] = 86400;
0 bedeutet nicht unendlich, sondern sofortiges Logout!
![]()
Das Test Anything Protocol (TAP) definiert eine textorientierte Kommunikationsschnittstelle zwischen Programmen, die Tests durchführen, den sogenannten Produzenten des Protokolls, und Steuer- und Auswertungsprogrammen, die Testprogramme aufrufen, deren Ergebnisse einsammeln und anzeigen, den sogenannten Konsumenten des Protokolls.
Die semi-offizielle Spezifikation des TAP Protokolls findet sich in dem Dokument Test::Harness::TAP.
Die Standard-Klasse zur Implementierung von Produzenten: Test::Builder.
Die Standard-Klasse zur Implementierung von Konsumenten: TAP::Parser.
Die genannten Klassen sind im Perl Core, also unter jeder neueren Perl-Installation von Hause aus verfügbar.
Die Klasse Test::Builder stellt eine Grundlage (Basisklasse) für das Schreiben von Testprogrammen dar. Die Klasse erlaubt, das Test Anything Protocol in vollem Umfang "zu sprechen". Allerdings implementiert die Klasse nur einen begrenzten Umfang an Testmethoden:
ok is_eq is_num isnt_eq isnt_num like unlike cmp_ok
Eine andere Möglichkeit besteht darin, das Core-Modul Test::More zu nutzen, das auf Test::Builder aufbaut und u.a. die sehr wichtige Funktion is_deeply (Vergleich von Datenstrukturen) zur Verfügung stellt.
Der Nachteil von Test::More ist allerdings, dass es nur eine Funktionssammlung, keine Klasse ist. Wer objektorientiert arbeiten möchte, findet das eventuell nicht so gut. Es lässt sich aber leicht eine saubere objektorientierte Überdeckung für Test::More schreiben, wenn man einige Punkte beachtet.
Hier eine objektorientierte Hülle für is_deeply, die analog auf alle Testfunktionen von Test::More ausgedehnt werden kann:
1 use Test::More (); 2 3 sub is_deeply { 4 my ($self,$ref1,$ref2,$text) = @_; 5 6 local $Test::Builder::Level = $Test::Builder::Level + 1; 7 return Test::More::is_deeply($ref1,$ref2,$text); 8 }
Erklärung der Besonderheiten:
Test::More wird geladen. Das leere Klammerpaar verhindert, dass Funktionen des Moduls importiert und damit der Namensraum der Klasse, in der wir die Methode definieren, verunreinigt wird.
Die Variable $Test::Builder::Level definiert den Abstand auf dem Callstack zwischen dem Aufrufer und der Testfunktion in Test::More. Dies wird für das Reporting der genauen Codestelle im Fehlerfall benötigt. Wir erhöhen den Abstand um 1, da wir unsere Methode in die Aufrufhierarchie einfügen. Für die Klassenvariable $Test::Builder::Level gilt dynamisches Scoping. Daher können wir ihren Wert via local lokal setzen und uns darauf verlassen, dass beim Verlassen des Blocks automatisch der ursprüngliche Wert wieder hergetellt wird.
Wir rufen die Funktion is_deeply mit Package-Präfix voll qualifiziert als Test::More::is_deeply auf, da wir die Test::More-Funktionen aus gutem Grund nicht in den Namensraum der Klasse importiert haben (siehe Erklärung zu Zeile 1).
![]()
Einer der weniger einleuchtenden Shell-Operatoren ist der Operator >&. Den Klassiker, die Umlenkung von stdout und stderr in eine Datei,
$ cmd >/tmp/file 2>&1
kennt jeder, der häufiger unter Unix unterwegs ist. Es stellt sich dabei aber immer leicht die Frage: Wie war das nochmal? Muss 2>&1 vor der Umlenkung >/tmp/file stehen? Oder dahinter? Gleichgültig ist die Reihenfolge jedenfalls nicht.
Die Beschreibung auf der Bash-Manpage ist recht knapp:
The operator [n]>&word is used to duplicate output file descriptors. If word expands to one or more digits, the file descriptor denoted by n is made to be a copy of that file descriptor. If n is not specified, the standard output (file descriptor 1) is used.
Das heißt, man kann den Operator N>&M als Zuweisung verstehen: Das Ausgabeziel (Terminal, Datei oder Pipe), das seitens des schreibenden Prozesses über Deskriptor M erreicht wird, wird von der Shell (zusätzlich) mit Deskriptor N verbunden. Alles, was der schreibende Prozess auf Desktiptor N schreibt, gelangt somit an das gleiche Ziel wie das, was er auf Deskriptor M schreibt. Liegen mehrere Umlenkungsoperationen vor, werden diese von links nach rechts ausgewertet. Es folgen einige Anwendungsfälle.
$ cmd1 2>&1 | cmd2
Deskriptor 1 (stdout) von cmd1 wird von der Shell mit der Pipe verbunden (|).
Deskriptor 2 (stderr) wird ebenfalls mit der Pipe verbunden (2>&1).
Ergebnis: stdout und stderr gehen auf die Pipe.
$ cmd1 2>&1 >/dev/null | cmd2
Deskriptor 1 (stdout) von cmd1 wird von der Shell mit der Pipe verbunden (|).
Deskriptor 2 (stderr) wird ebenfalls mit der Pipe verbunden (2>&1).
Deskriptor 1 (stdout) wird mit /dev/null verbunden (>/dev/null).
Ergebnis: stderr geht auf die Pipe, stdout geht nach /dev/null.
$ cmd 3>&1 1>&2 2>&3 3>&-
Deskriptor 3 geht auf das gleiche Ziel wie Deskriptor 1 (3>&1).
Deskriptor 1 geht auf das gleiche Ziel wie Deskriptor 2 (1>&2).
Deskriptor 2 geht auf das gleiche Ziel wie Deskriptor 3 (2>&3).
Gib Deskriptor 3 frei (3>&-).
Ergebnis: stdout und stderr sind vertauscht.

Ein ausgezeichnetes Programm zur Visualisierung und interaktiven Bearbeitung von Unterschieden zwischen Dateien ist meld. Es unterstützt
Vergleich zweier Dateien:
$ meld FILE1 FILE2
Die Unterschiede werden grafisch dargestellt. Innerhalb differierender Zeilen werden die Unterschiede bis auf Zeichenebene markiert. Die Dateien können mithilfe des eingebauten Editors bearbeitet werden. Dabei entstehende Differenzen werden just-in-time neu berechnet und angezeigt. Mittels Klick auf einen der eingeblendeten Pfeile (s. Sceenshot) wird eine Änderung insgesamt in die gegenüberliegende Datei übertragen, die Differenz also eleminiert.
Links:
![]()
Die in ffmpeg verfügbaren Filter werden bei Angabe der Option -filters angezeigt. Leider ist die Liste unsortiert, was sich durch folgende Kommandozeile beheben lässt:
$ ffmpeg -filters 2>/dev/null | grep -v ^Filters: | sort
![]()
Ein Video, das interlaced aufgezeichnet wurde, muss vor einer weiteren Verarbeitung deinterlaced werden. Der entsprechende Filter von ffmpeg heißt yadif (Yet Another DeInterlacing Filter). Anwendung:
$ ffmpeg -i INFILE -vf yadif ... OUTFILE
In älteren Versionen:
$ ffmpeg -i INFILE -filter:v yadif ... OUTFILE
Zwar besitzt ffmpeg die Option -deinterlace, diese soll laut Manpage jedoch nicht genutzt werden, da das Ergebnis von geringer Qualität sei.

Fertige Teile eines Filmprojekts können sukzessive gerendert und später mit cat zusammengefügt werden, wenn als Format MPEG-2 verwendet wird. Damit lässt sich das Neurendern des Films auf das Rendern des geänderten Teils verkürzen.
Mit der Option Selected Zone des Render-Dialogs von kdenlive wird ein Ausschnitt des Films gerendert. Fertige Teile müssen nur einmal gerendert werden und können mit einem neuen Teil per
$ cat CLIP1.mpg CLIP2.mpg ... >MOVIE.mpg
zum vollständigen Film zusammengefügt werden. Dies geht wesentlich schneller als den gesamten Film zu rendern.
Dieses Vorgehen setzt natürlich voraus, dass alle Clips mit den gleichen Einstellungen (Geometrie, Bitrate usw.) erstellt werden.
![]()
Wechseldatenträger (USB Festplatten, Memory Sticks) werden unter Linux automatisch nach /media/<name> gemountet. Hat der Datenträger ein Label, wird dieses als (sprechender) <name> verwendet.
Label setzen:
# tune2fs -L <name> <device>

Zeige die Liste der geöffneten TCP-Ports und welche Programme sie nutzen:
# netstat -pant -p : Zeige PID und Programmnamen -a : Zeige sowohl Listening- als auch Non-Listening-Sockets -n : Zeige numerische Werte statt symbolischer Host-, Port- und Benutzernamen -t : Zeige TCP-Ports (-u UDP-Ports)
![]()
Streamripper ist ein Kommandozeilenprogram, mit dem es möglich ist, SHOUTcast- und Icecast-Internetradiosendungen aufzuzeichnen. Das geht so:
Rippe Stream URL, speichere die Dateien im aktuellen Verzeichnis und erzeuge einen Relay-Server auf Port 8000:
$ streamripper URL -r
Gib den Stream parallel über den von streamripper erzeugten Relay-Server wieder:
$ cvlc -q http://localhost:8000
Beispiel: Speichere die Songs des Kanals SomaFM/Groove Salad im Unterverzeichnis groove-salad und überschreibe eine existierende Datei nur, wenn sie größer ist:
$ streamripper http://somafm.com/groovesalad256.pls -r -d groove-salad -o larger
![]()
Gegeben ist eine Tabelle <table> mit einer Kolumne <x>, deren Wert frei manipuliert werden kann, und einer Kolumne <y>, deren Wert funktional von <x> abhängt (also nicht frei manipuliert werden kann). Die Abbildung von <x> auf <y> ist in einer Lookup-Tabelle <lookup_table> definiert, die jedem Wert <x> den entsprechenden Wert <y> zuordnet.
Aufgabe: Der <y>-Wert soll in <table> gespeichert werden und stets konstitent zu <x> sein. Der Wert von <y> soll nicht erst bei Abfrage ermittelt werden. Im Prinzip ist das eine unerwüschte Redundanz, die aber aus praktischen Gründen sinnvoll sein kann.
Die Anforderung lässt sich durch einen BEFORE INSERT OR UPDATE-Trigger erfüllen, der beim Einfügen oder Ändern in <table> den <y>-Wert via <x> in <lookup_table> ermittelt und auf <table>.<y> überträgt.
Es folgt die Lösung für Oracle und PostgreSQL.
1 CREATE OR REPLACE TRIGGER <tigger> BEFORE INSERT OR UPDATE 2 ON <table> FOR EACH ROW 3 BEGIN 4 SELECT 5 <y> 6 INTO 7 :new.<y> 8 FROM 9 <lookup_table> 10 WHERE 11 <x> = :new.<x>; 12 END;
1 CREATE FUNCTION <trigger_func>() RETURNS trigger AS $$ 2 BEGIN 3 SELECT 4 <y> 5 INTO STRICT 6 NEW.<y> 7 FROM 8 <lookup_table> 9 WHERE 10 <x> = NEW.<x>; 11 12 RETURN NEW; 13 END; 14 $$ LANGUAGE plpgsql; 15 16 CREATE TRIGGER <trigger> BEFORE INSERT OR UPDATE 17 ON <table> FOR EACH ROW 18 EXECUTE PROCEDURE <trigger_func>();
Der Code ist bei beiden Datenbanksystemen ähnlich, die Unterschiede sind im Wesentlichen:
Die Prozedur kann bei Oracle als Teil des Trigger definiert werden, was den Code einfach und elegant macht. Bei PostgreSQL ist eine spezielle, vom Trigger getrennte Prozedurdefinition erforderlich.
Der Bezeichner für die neue Tabellenzeile ist bei Oracle :new, bei PostgreSQL NEW. Bei PostgreSQL muss diese Zeile von der Trigger-Prozedur zurückgeliefert werden. Bei Oracle wird nichts zurückgeliefert.
PostgreSQL generiert bei INTO STRICT automatisch eine Exception, wenn durch das SELECT keine oder mehr als eine Zeile getroffen wird. Dies ist ein kostenloser Paranoia-Test für die Daten in <lookup_table>.
![]()
Startup-Datei anlegen/ändern:
$ vi ~/.psqlrc
Die Kommandos in der Datei führt der Interpreter beim Start aus. Hier können persönliche Einstellungen vorgenommen werden. Z.B. kann man dort den Pager aus- und die Zeitmessung einschalten.
Pager abschalten:
<db>=# \pset pager off Pager usage is off.
Zeitmessung einschalten:
<db>=# \timing on Timing is on.
Nützliche interaktive Kommandos:
Liste der Schemata:
<db>=# \dn ...
Liste der Tabellen eines Schemas:
<db>=# \dt <schema>.* ...
Tabelle, View oder Sequenz beschreiben:
<db>=# \d <object> ...
Spezielle SQL-Anweisungen:
Liste der Runtime-Parameter:
<db>=# show all; ...

Auf dem Adroid Developer Portal ist unter dem Einstiegspunkt Installing the SDK beschrieben, wie eine Android-Entwicklungsumgebung aufgesetzt wird. Die Information ist allerdings über etliche Seiten verstreut, weswegen ich die Schritte hier zusammenfasse.
Unser Ziel ist die Einrichtung einer Android-Entwicklungsumgebung unter Linux mit anschließender Erstellung eines "Hello World"-Programms, das wir unter Android ausprobieren können. Wir arbeiten an der Kommandozeile ohne die Verwendung einer IDE (Eclipse), denn wir wollen das Android SDK zunächst direkt, ohne den Mantel einer IDE kennen lernen.
Alle hier genannten Dateinamen, Versionsnummern und Screenshots beziehen sich auf den Zeitpunkt der Erstellung des Blog-Eintrags und können sich danach natürlich geändert haben. Anhand der im Text angegebenen Links können diese Angaben geprüft und ggf. sinngemäß ersetzt werden.
Wir setzten voraus, dass das Java SE JDK und Ant auf dem System bereits installiert sind. Sollte das nicht der Fall sein, lässt sich dies unter Debian leicht nachholen:
$ apt-get install openjdk-6-jdk $ apt-get install ant
1. Als erstes legen ein Verzeichnis android an. Der Name und der Ort im Dateisystem sind gleichgültig. In diesem Verzeichnis befindet sich nach Abschluss der folgenden Schritte die Android Entwicklungsumgebung mit dem "Hello World"-Programm.
$ mkdir ~/android $ cd ~/android
2. Als nächstes laden wir das SDK Starter Package von der http://developer.android.com/sdk/index.html herunter. Für Linux ist dies die Datei android-sdk_r16-linux.tgz.
$ wget http://dl.google.com/android/android-sdk_r16-linux.tgz $ tar xvzf android-sdk_r16-linux.tgz
Der Tarball entpackt sich in das Subverzeichnis android-sdk-linux. Das SDK Starter-Package enthält noch nicht die volle Entwicklungsumgebung, sondern
$ PATH=~/android/android-sdk-linux/tools:$PATH
$ android
$ PATH=~/android/android-sdk-linux/platform-tools:$PATH
http://developer.android.com/guide/developing/devices/managing-avds.html
Wiederum android aufrufen und
$ android Menüpunkt "Tools/Manage AVDs..." Name: Target:
http://developer.android.com/resources/tutorials/hello-world.html
$ android create project \ --package com.example.helloandroid \ --activity HelloAndroid \ --target 2 \ --path project/HelloAndroid
$ cd project/HelloAndroid
$ ant debug
Buildfile: /home/fs/android/project/HelloAndroid/build.xml
...
$ adb install bin/HelloAndroid-debug.apk
106 KB/s (4871 bytes in 0.044s)
pkg: /data/local/tmp/HelloAndroid-debug.apk
Success
![]()
Das Java SE (Standard Edition) Devolpment Kit (JDK) gibt es hier. Wir folgen dem Workflow und laden die gewünschten Archiv-Dateien herunter.
Für Standard Edition 7 sind es für Linux x86 die Dateien:
Wir gehen in ein beliebiges Verzeichnis (z.B. /opt/java) und entpacken die Dateien dort:
$ tar xvzf jdk-7u2-linux-i586.tar.gz $ tar xvzf jdk-7u2-linux-i586-demos.tar.gz $ unzip jdk-7u2-apidocs.zip $ mv docs jdk1.7.0_02
Im Unterverzeichnis jdk1.7.0_02 befindet sich nun das JDK einschließlich Dokumentation (Unterverzeichnis docs mit docs/index.html als Startseite) und Beispielen (Unterverzeichnisse demo und samples).
Wir nutzen diese Java-Installation, indem wir das Environment darauf einstellen:
$ export JAVA_HOME=`pwd`/jdk1.7.0_02 $ PATH=$JAVA_HOME/bin:$PATH
Programm "Hello world":
$ vi HelloWorldApp.java
class HelloWorldApp {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
Klasse kompilieren und ausführen:
$ javac HelloWorldApp.java $ java HelloWorldApp Hello World!
Für Standard Edition 6 sind es für Linux x86 nur zwei Archiv-Dateien, da das JDK-Archiv die Beispiele mit enthält:
Das Auspacken verläuft geringfügig anders, da die Daten in ein Shell-Archiv eingepackt sind:
$ sh jdk-6u30-linux-i586.bin $ unzip jdk-6u30-apidocs.zip $ mv docs jdk1.6.0_30
Das JDK befindet sich in Unterverzeichnis jdk1.6.0_30.

Eine leistungsfähiges Werkzeug zur Verwaltung und Konvertierung von eBooks ist das eBook Management-System Calibre.
Installation unter Debian:
# apt-get install calibre
$ calibredb add FILE.azw
Dafür existiert das Calibre-Plugin K4MobiDeDRM. Siehe:
eBook Wiki (Formats, Free Books, Hardware, Software, ...): http://wiki.mobileread.com/

Hat man die Kontrolle über ein Linux-System verloren (es bootet nicht mehr, Anmelden als root ist nicht möglich, o.ä.) ist es nützlich ein Rescue-System zu haben, von dem aus man das defekte System untersuchen und ggf. reparieren kann.
Ein solches Rescue-System lässt sich leicht auf einem USB-Stick installieren. Hierzu holt man sich das Image eines Live-Systems von einem Debian-Mirror und kopiert es 1:1 auf den USB-Stick.
Die Live-Systeme von Debian finden sich unter http://www.debian.org/CD/live/. Sie basieren auf dem aktuellen Stable-Release für die Architekturen i386 und amd64 und unterscheiden sich in der Desktop-Umgebung (Gnome, KDE, LXDE, Xfce oder Terminal):
debian-live-<version>-<arch>-gnome-desktop.<ext> debian-live-<version>-<arch>-kde-desktop.<ext> debian-live-<version>-<arch>-lxde-desktop.<ext> debian-live-<version>-<arch>-xfce-desktop.<ext> debian-live-<version>-<arch>-rescue.<ext> debian-live-<version>-<arch>-standard.<ext> Hierbei ist: <version> die Versionsnummer des Stable-Release (aktuell 6.0.3) <arch> die Prozessor-Architektur (amd64 oder i386) <ext> die Dateiendung .iso oder .img
Da jedes Live-System aus nur einer Datei besteht und bootfähig ist, gestaltet sich das Herunterladen und Installieren sehr einfach:
# wget <file> # dd if=<file> of=/dev/sd<x> bs=1M # sync Hierbei ist: <file> eine der obigen Dateien <x> der Device-Buchstabe des USB-Stick
Fertig.
Vorsicht! Ein falscher Device-Name kann Daten auf anderen Geräten als dem USB-Stick oder gar das System komplett zerstören. Er sollte daher akribisch geprüft werden. Er lässt sich z.B. mit fdisk -l ermitteln. Sollte der Stick beim Einstecken automatisch gemountet worden sein, was wahrscheinlich ist, muss er vor Ausführung des dd-Kommandos erst mit umount ausgehängt werden.
Zum Booten vom Stick stellt man die Bootreihenfolge im BIOS-Setup entweder dauerhaft um oder ändert sie "on the fly" beim Bootvorgang, durch Drücken der Taste, die eine Auswahl des Boot-Device erlaubt (z.B. ESC). Beim Eee PC Asus 1001PX lässt sich der Stick nur mit der letzterer Methode booten. Ein automatisches Booten vom Stick funktioniert nicht, es wird immer von der Festplatte gebootet.
Die Images für das Erzeugen eines Debian-Installers für Testing auf einem USB-Stick (oder einer CD) befinden sich hier: http://www.debian.org/devel/debian-installer/
Das Businesscard-Image lässt sich vereinfacht auf den USB-Stick bringen, da es in die boot.img-Partition passt. Das NetInst-Image von Testing ist dafür zu groß (siehe NetInst-ISO-Image).
# wget -N http://d-i.debian.org/daily-images/<arch>/daily/\
hd-media/boot.img.gz
# wget -N http://cdimage.debian.org/cdimage/daily-builds/daily/\
arch-latest/<arch>/iso-cd//debian-testing-<arch>-businesscard.iso
# zcat boot.img.gz >/dev/sd<x>
# mount /dev/sd<x> /mnt
# cp debian-testing-<arch>-businesscard.iso /mnt
# umount /dev/sd<x>
Hierbei ist:
<arch> die Prozessor-Architektur (i386, amd64, ...)
<x> der Device-Buchstabe des USB-Stick
Das NetInst-Image muss wegen seiner Größe mittels Syslinux auf den USB-Stick gebracht werden. Syslinux benötigt eine Partitionierung mit einer FAT16-Partition à la
Device Boot Start End Blocks Id System /dev/sdc1 * 2048 7829503 3913728 6 FAT16
Wie diese erstellt wird, siehe http://wiki.debian.org/BootUsb#Partitioning_the_USB_key.
Ferner werden folgende Pakete benötigt: mbr, mtools, syslinux.
# wget http://d-i.debian.org/daily-images/<arch>/daily/hd-media/vmlinuz
# wget http://d-i.debian.org/daily-images/<arch>/daily/hd-media/initrd.gz
# http://cdimage.debian.org/cdimage/daily-builds/daily/arch-latest/\
<arch>/iso-cd/debian-testing-<arch>-netinst.iso
# install-mbr /dev/sd<x>
# mkdosfs /dev/sd<x>1
mkdosfs 3.0.12 (29 Oct 2011)
# syslinux -i /dev/sd<x>1
# mount /dev/sd<x>1 /mnt
# cp vmlinuz initrd.gz debian-testing-i386-netinst.iso /mnt
# cat >/mnt/syslinux.cfg
default vmlinuz
append initrd=initrd.gz
^D
# umount /dev/sd<x>1
Hierbei ist:
<arch> die Prozessor-Architektur (i386, amd64, ...)
<x> der Device-Buchstabe des USB-Stick
NAME
debian-to-usb - Erzeuge bootbaren USB-Stick mit Debian Image
USAGE
debian-to-usb [OPTIONS] IMAGE DEVICE
debian-to-usb --get net-inst
debian-to-usb --get businesscard-inst
OPTIONS
--verbose=BOOL (Default: 1)
Gib die ausführenden Kommandos aus.
--help
Diese Hilfe.
IMAGE
Der Dateiname eines Debian Live-Image mit der Endung .iso oder .img
oder einer der beiden Bezeichner
businesscard-inst
Erzeuge Installer aus Businesscard-Image.
net-inst
Erzeuge Installer aus NetInst-Image.
DEVICE
Der Device-Name, unter dem der USB-Stick angesprochen wird. Z.B.
"/dev/sdb". Das Device darf nicht gemountet sein.
Vorsicht! Ein falscher Device-Name kann Daten auf anderen Geräten
oder gar das System zerstören. Er sollte daher akribisch geprüft
werden. Er lässt sich z.B. mit "fdisk -l" ermitteln.
AUTHOR
Frank Seitz, http://www.fseitz.de/
COPYRIGHT
Copyright (C) Frank Seitz, 2012
![]()
Antragstellung: über Strato V-Server Account, SSL-Zertifikatstyp: thawte SSL123, Kosten: 3,90 EUR/Monat.
# openssl genrsa -des3 -out mydomain-de.key 2048 Generating RSA private key, 2048 bit long modulus ...
Der Private Key wird hier im Klartext ohne Passphrase erzeugt. Es ist praktischer, keine Passphrase zu verwenden, da sonst beim Neustart des HTTP-Servers die Passphrase manuell eingegeben werden müsste.
# openssl req -new -key mydomain-de.key -out mydomain-de.csr ... Country Name (2 letter code) [AU]:DE State or Province Name (full name) [Some-State]:BUNDESLAND Locality Name (eg, city) []:STADT Organization Name (eg, company) [Internet Widgits Pty Ltd]:ORGANISATION Organizational Unit Name (eg, section) []: Common Name (eg, YOUR name) []:mydomain.de Email Address []:me@mydomain.de Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []:
Der Certificate Request wird bei Thawte eingereicht. Dies wickelt Strato ab. Die Daten werden über ein Webformular unter "SSL-Verwaltung/Easy SSL" erhoben. Thawte meldet sich per Mail. Auf dem Weg und per Bestätigung übers Web findet die Validierung statt. Der Certificate Request hat später für die Verwendung von SSL keine Bedeutung.
Das signierte Zertifikat wird von Thawte nach Validierung geliefert und kann bei Strato unter "SSL-Verwaltung/Easy SSL" abgerufen werden. Das Zertifikat wird als mydomain-de.crt gespeichert.
Installation des Private Key und des Zertifikats auf dem Server:
# mv mydomain-de.csr /etc/ssl/certs # mv mydomain-de.key /etc/ssl/private # chown root.root /etc/ssl/private # chmod 600 /etc/ssl/private
Apache-Konfiguration:
<IfModule mod_ssl.c>
<VirtualHost *:443>
...
SSLEngine on
SSLCertificateFile /etc/ssl/certs/mydomain-de.crt
SSLCertificateKeyFile /etc/ssl/private/mydomain-de.key
...
</VirtualHost>
</IfModule>
![]()
Installation von davfs (Debian):
# apt-get install davfs2
Dateisystem manuell mounten:
# mkdir /hidrive # mount -t davfs https://webdav.hidrive.strato.com /hidrive Username: myname Password: mypassword
Eintrag zur fstab hinzufügen:
# vi /etc/fstab ... https://webdav.hidrive.strato.com /hidrive davfs noauto,user 0 0
Dateisystem vereinfacht manuell mounten:
# mount /hidrive
Dateibaum DIR per rsync in HiDrive Nutzerverzeichnis übertragen, ohne Verwendung des Mountpoint:
$ rsync -avz -e ssh DIR myname@rsync.hidrive.strato.com:/users/myname/
Unter "Einstellungen/Kontenverwaltung/OpenSSH-Schlüssel" kann der Public-Key des aufrufenden Benutzers hochgeladen werden, so dass sich die Passworteingabe vermeiden lässt.
![]()
**004*333**30#<abheben>
** Definieren
004* Umleitung bei Abwesenheit, Unerreichbarkeit, besetzt
333 Nummer, auf die umgeleitet wird (hier: FONIC-Mailbox)
** Dienstkennung (leer)
30 Zeitspanne in Sekunden (5 bis 30 möglich)
# Endekennung des GSM-Befehls
<abheben> GSM-Code an Provider übermitteln
Antwort:
Rufweiterleitung
Registrierung war erfolgreich
Bei Abwesenheit, Unerreichbarkeit (kein Netz oder Telefon ist ausgeschaltet) oder besetzt wird der Anrufer auf die FONIC-Mailbox weitergeleitet. Bei Abwesenheit klingelt das Telefon bis zur Weiterleitung die maximal möglichen 30 Sekunden.
##004#<abheben> Antwort: Rufweiterleitung Löschvorgang erfolgreich
Alle bedingten Rufweiterleitungen (Abwesenheit, Unerreichbarkeit, besetzt) werden gelöscht. Die Mailbox geht anschließend nicht mehr ran. Der Anrufer hört eine Ansage des Providers, kann aber keine Nachricht hinterlassen.
*101#<abheben> Antwort: Ihr FONIC Guthaben beträgt: <X> EUR Tipp: Laden Sie Ihr Guthaben bequem und einfach vom Bankkonto auf. Infos unter www.fonic.de
*#06# Antwort (des Telefons): TTTTTTTTSSSSSSC TTTTTTTT Type Approval Code SSSSSS Seriennummer C Prüfziffer
Die IMEI identifiziert das Telefon eindeutig. Im Falle eines Garantiefalls oder Diebstahls kann es notwendig bzw. vorteilhaft sein sie zu wissen. Genauere Information: http://de.wikipedia.org/wiki/IMEI
Amazon Warehouse Deals hat mir einen Rückläufer des Google Phone Nexus S i9023 für ca. 70% des Neupreises verkauft. Das Smartphone wurde nach Angaben von Amazon auf Funktionsfähigkeit geprüft und für "gut" befunden.
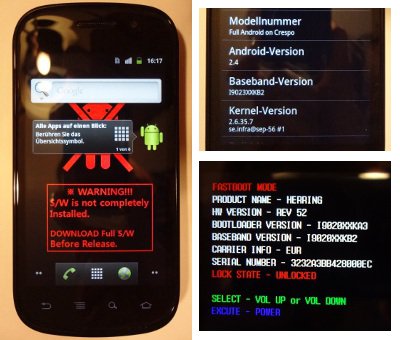
Leider ist das Gerät unbrauchbar. Die rote Meldung auf dem Display, die einem nach dem Einschalten unübersehbar ins Auge sticht, deutet bereits darauf hin:
WARNING!!! S/W is not completely installed. DOWNLOAD Full S/W Before Release.
Eine genauere Prüfung ergab, dass die Installation tatsächlich defekt was. Es handelte sich anscheinend um eine Entwicklerversion des Smartphone, auf welcher unvollständig Android 2.4 installiert war - eine Version, die es zum Zeitpunkt der Lieferung offiziell gar nicht gab. Im Netz habe ich keine aktuelle, installierbare Android 2.3.6 Komplettversion gefunden (nur Updates von der vorherigen Version) und das Phone daher reklamiert und an Amazon zurückgeschickt.
Dass das Gerät vor Auslieferung geprüft wurde, kann also nicht stimmen. Eine unerfreuliche Sache, die mich einige Stunden gekostet hat.

Die Ausgaben des Cisco vpnclient sind nicht unbedingt informativ, wenn etwas schief geht. Hier hilft die Aktivierung und Auswertung des Log. Das Logging wird in der Datei vpnclient.ini aktiviert. Hierzu wird die Option EnableLog=1 gesetzt und alle LogLevel-Einträge auf LogLevel=3.
Das Logging wird gestartet durch
$ ipseclog /tmp/vpnclient.log
Die Logmeldungen werden nach /tmp/vpnclient.log geschrieben.
Das für frühere Kernel-Versionen kompilierte Kernel-Modul cisco_ipsec crasht bei Aufruf des Cisco vpnclient unter Linux 2.6.38. Das System ist danach nur noch eingeschränkt nutzbar.
Das Problem wurde auf http://forum.tuxx-home.at diskutiert und behoben. Der Patch dort funktioniert allerdings nicht, da der Patch, den man nur per Copy&Paste erhalten kann, in der Form defekt ist.
Ich habe diesen händisch restauriert und aus den Patches
http://www.lamnk.com/download/fixes.patch (existiert nicht mehr)
http://forum.tuxx-home.at/viewtopic.php?f=15&t=1293 (defekter Copy&Paste-Patch)
einen einzigen Patch erstellt, der auf das originale Cisco-Archiv angewendet werden kann.
Cisco-Archiv herunterladen
# wget http://projects.tuxx-home.at/ciscovpn/clients/linux/4.8.02/\ vpnclient-linux-x86_64-4.8.02.0030-k9.tar.gz
Patch für Linux 2.5.38+ herunterladen
# wget http://fseitz.de/download/vpnclient.patch-2.6.38
Cisco-Archiv entpacken
# tar xvzf vpnclient-linux-x86_64-4.8.02.0030-k9.tar.gz
Ins vpnclient-Verzeichnis wechseln
# cd vpnclient
Patch anwenden
# patch <../vpnclient.patch-2.6.38
Cisco Software kompilieren
# make
Cisco Software installieren
# ./vpn_install
![]()
(dieser Eintrag wird fortgeführt)
Die Eingabeelemente eines Web-Formulars empfangen ihre Werte idealerweise aus dem Request-Objekt. Drei Fälle sind zu unterscheiden:
Auffrischen: Das Request-Objekt enthält die Daten eines vorangegangenen Submit. Es ist nichts zu tun. Dies ist typischerweise bei einem Fehler der Fall oder wenn in Folge einer Benutzerauswahl ein Neuaufbau des Formulars erforderlich ist.
Bearbeiten: Die Daten kommen aus der Datenbank. Die Daten werden selektiert und auf das Request-Objekt kopiert, ggf. nach einer geeigneten Transformation.
Neueingabe: Es gibt keine äußere Datenquelle. Das Request-Objekt wird mit Defaultwerten für die Formularfelder initialisiert.
In Perl:
| 1 | # Request-Objekt für Webformular manipulieren |
| 2 | |
| 3 | my $action = $cgi->get('action'); |
| 4 | my $objId = $cgi->get('obj_id'); |
| 5 | |
| 6 | if ($action) { |
| 7 | # Fall 1: nichts tun |
| 8 | } |
| 9 | elsif ($objId) { |
| 10 | # Fall 2: Datenbank-Inhalt selektieren und auf Request-Objekt kopieren |
| 11 | my $obj = Object->lookup($db,obj_id=>$objId); |
| 12 | $obj->copyTo($cgi); |
| 13 | } |
| 14 | else { |
| 15 | # Fall 3: Request-Objekt mit Defaultwerten initialisieren |
| 16 | $cgi->set(@keyVal); |
| 17 | } |
| 18 | |
| 19 | # Ab hier Felder aus dem Request-Objekt initialisieren |
$cgi ist das Request-Objekt.
$action zeigt an, ob die Daten nach einem Submit an das Formular zurückgeliefert wurden. Die Formularwerte kommen dann aus den CGI-Parametern.
$objId ist die Id des Modell-Objekts. Wenn $action nicht gesetzt ist, wird das Formular aus dessen Attributen initialisiert.
Object ist die Modell-Klasse. Diese implementiert die Methode copyTo(), welche die Datensatz-Attribute auf das Request-Objekt kopiert.
$db ist das Datenbank-Objekt, über das auf ddie Datenbank zugegriffen wird.
@keyVal ist die Liste aus Schlüssel/Wert-Paaren für die Initialisierung mit den Defaultwerten.
![]()
SELECT col1, ..., colN, COUNT(*) FROM tab GROUP BY col1, ..., colN HAVING COUNT(*) > 1
col1, ..., colN sind die Kolumnen, über denen die Dubletten-Eigenschaft geprüft wird.
![]()
Server herunterfahren
Inhalt des Datadir löschen
$ rm -r DATADIR/*
Datadir initialisieren
$ mysql_install_db --user=mysql --ldata=DATADIR
Server wieder hochfahren
![]()
Eine elegante Möglichkeit, mehrere MySQL-Instanzen auf einem Server zu betreiben, bietet das Programm mysqld_multi. Es erweitert die Konfigurationsdatei /etc/my.cnf um Abschnitte für mehrere MySQL-Serverinstanzen [mysqld#] (wobei # die jeweilige Instanznummer bezeichnet). In den Abschnitten werden den Instanzen getrennte Datadirs, Sockets, Ports, Pid-Files usw. zugewiesen.
mysqld_multi ist das Frontend-Programm zum Starten und Stoppen der einzelnen Instanzen, à la
$ mysqld_multi start 2
Eine Beispielkonfiguration, die auf die eigenen Verhältnissse angepasst und in my.cnf eingesetzt werden kann, liefert das Kommando
$ mysqld_multi --example
Die ausführliche Doku ist auf der Manpage zu finden:
$ man mysql_multi
![]()
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) http://www.joelonsoftware.com/articles/Unicode.html
Convert latin1 to UTF-8 in MySQL: http://en.gentoo-wiki.com/wiki/Convert_latin1_to_UTF-8_in_MySQL
Zeichensätze und Sortierfolgen im Allgemeinen: http://dev.mysql.com/doc/refman/5.1/de/charset-general.html
Zeichenkodierungen oder ?Warum funktionieren meine Umlaute nicht??: http://perlgeek.de/de/artikel/charsets-unicode
![]()
$ svn copy svn://HOST:PORT/trunk svn://HOST:PORT/branches/BRANCH -m MSG HOST : Name des SVN Host PORT : Portnummer (falls der Server nicht auf dem Standardport 3690 läuft) BRANCH : Name des Branch, welcher frei gewählt werden kann MSG : Logmeldung zur Brancherzeugung $ svn up /DIR/branches/BRANCH DIR : Wurzelverzeichis des ausgecheckten Repository (Trunk+Branches)
$ cd /DIR/branches/BRANCH $ svn merge svn://HOST:PORT/trunk
Das Aktualisieren des Branch mit den Änderungen im Trunk sollte so oft wie möglich passieren, damit nicht zu viele Konflikte auflaufen.
$ cd /DIR/trunk $ svn merge --reintegrate svn://HOST:PORT/branches/BRANCH
$ svn delete /DIR/branches/BRANCH
Nach der Rückintegration des Branch in den Trunk ist der Branch nutzlos geworden und sollte gelöscht werden. Im Repository bleibt er vorhanden, es wird ohne Angabe der letzten Revision Number bei einem Update in /DIR/branches aber keine (unerwünschte) Working Copy mehr erzeugt.
Freie Online-Version von Version Control with Subversion
![]()
Die Lautstärke kann per Audio-Filter geändert werden:
$ ffmpeg ... -af volume=FACTOR ... FACTOR: 0 .. N (0.5 halbiert die Lautstärke, 2 verdoppelt sie)
In älteren ffmpeg-Versionen kann die Lautstärke mit der Option -vol verändert werden. Diese Option ist auf der Manpage (Version 0.6.2) nicht dokumentiert.
$ ffmpeg -i INPUT_FILE -vol N OUTPUT_FILE
Der Lautstärke-Wert N ist eine Angabe in "Byte Percent", d.h. 256 = 100%. Mit dem Wert 512 wird die Lautstärke also verdoppelt und mit dem Wert 128 wird sie halbiert.
Media Formats Explained: http://www.dr-lex.be/info-stuff/mediaformats.html
Video Bitrate Calculator: http://www.dr-lex.be/info-stuff/videocalc.html
Bitraten-Rechner: http://www.videohelp.com/calc.htm
Offizielle YouTube APIs und Tools. Data API für Upload, Custom Player etc.: http://code.google.com/apis/youtube/overview.html
Kdenlive User Manual: http://www.kdenlive.org/user-manual
Kdenlive Wiki: http://en.wikibooks.org/wiki/Kdenlive
Videohokuspokus mit FFmpeg: http://spielwiese.la-evento.com/hokuspokus/index.html
FFmpeg Homepage: http://www.ffmpeg.org/
Audacity Manual: http://manual.audacityteam.org/
How to Create a Time Lapse Video using FFMPEG: http://pr0gr4mm3r.com/linux/how-to-create-a-time-lapse-video-using-ffmpeg/
Eine Anleitung zum Installieren von Oracle 11g unter Debian, die versucht, mögliche Probleme von vornherein auszuschließen, dafür aber umfangreiche Vorarbeiten verlangt, findet sich hier: http://edin.no-ip.com/blog/hswong3i/oracle-database-11g-release-1-debian-sid-howto
Meine Anleitung hat das Ziel, die Voraussetzungen für den Aufruf des Installers zu schaffen. Da der Installer selbst den Softwarestand und die Kernelparameter prüft, können Anpassungen auch bei laufender Installation vogenommen werden.
 Abbildung 1: Allgemeine Konfigurationsangaben im Installer
Abbildung 1: Allgemeine Konfigurationsangaben im Installer
Dateien von Oracle.com herunterladen: Download 11g Enterprise Edition (Hierfür ist ein OTN-Konto nötig)
# addgroup --system dba # adduser --system --home /opt/oracle --shell /bin/bash --ingroup dba --gecos 'Oracle DBA' oracle # passwd oracle
Auf Benutzer oracle wechseln, unter dessen Rechten wird die weitere Installation durchgeführt:
# su - oracle $ unzip linux_11gR2_database_1of2.zip $ unzip linux_11gR2_database_2of2.zip
Die Dateien werden von unzip in ein Unterverzeichnis database entpackt. Wo entpackt wird, ist egal. Die entpackten Dateien werden nur während der Installation gebraucht. Nach der Installtion kann das gesamte Verzeichnis gelöscht werden.
Wichtig: Wurde der Desktop unter einem anderen Benutzer als oracle gestartet, muss der Benutzer den Desktop für den Zugriff des Benutzers oracle freigeben, da dieser den Installer aufruft. Geschieht die Freigabe nicht, stirbt der Installer nach einigen Sekunden mit der wenig aussagekräftigen Fehlermeldung
No protocol specified [Java Stacktrace]
Die Freigabe erfolgt mit dem Kommando:
<user>$ xhost +
Als Benutzer oracle ausführen:
$ cd database $ ./runInstaller
Der Installer führt den Benutzer durch die Installation, nimmt zahlreiche Prüfungen vor und schreibt ein Logfile, das bei Problemen konsultiert werden kann.
Unstimmigkeiten können parallel behoben werden, Prüfungen und fehlgeschlagene Schritte können immer wieder neu durchgeführt werden bis es klappt.
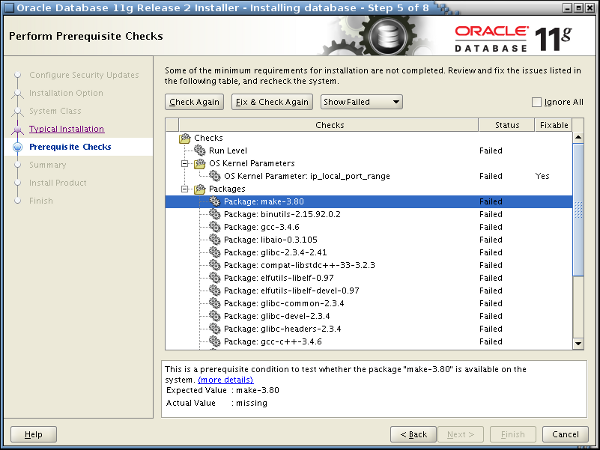 Abbildung 2: Kernel- und Software-Prüfungen durch den Installer
Abbildung 2: Kernel- und Software-Prüfungen durch den Installer
/etc/oraInst.loc /etc/oratab
/opt/oracle/app/*
/usr/local/bin/oraenv /usr/local/bin/coraenv /usr/local/bin/dbhome
/var/opt/oracle/<DATABASE>/*
![]()
Per Default wird bei mod_perl derselbe Perl-Interpreter für alle Virtual Hosts genutzt. Das kann zu Problemen führen, wenn die Applikationen unterschiedliche Versionen derselben Module nutzen.
Dies kann bei mod_perl 2.0 mit der PerlOption +Clone ausgeschlossen werden:
<VirtualHost ...> PerlOptions +Clone </VirtualHost>
Die Option +Clone bewirkt, dass für den betreffenden Virtual Host ein eigener Interpreter-Pool genutzt wird. Dieser entsteht durch Klonen des Parent-Interpreters (welcher eventuell schon eine Startup-Initialisierung erfahren hat).
Ein Interpreter-Pool mit einem gänzlich neuen Parent-Interpreter wird bei Angabe von +Parent erzeugt:
<VirtualHost ...> PerlOptions +Parent </VirtualHost>
Um dem Interpreter einen (oder mehrere) eigene Suchpfade mitzugeben, kann die Perl Standard-Option -I verwendet werden:
PerlSwitches -I/var/www1/modules
![]()
Finde in Dateibaum DIR alle Dateinamen mit Sonderzeichen, also mit Zeichen, die nicht im ASCII-Zeichensatz liegen:
find DIR | perl -ne "print if /[^[:ascii:]]/"
Umlaute und andere Non-ASCII-Zeichen in Dateinamen sind problematisch und sollten vermieden werden, wenn nicht garantiert ist, dass systemweit mit ein und demselben Encoding gearbeitet wird, denn das Encoding eines Dateinamens lässt sich aus diesem nicht herleiten.
Neueste Seamonkey-Version (Tarball) holen von
http://www.seamonkey-project.org/releases/
Einrichten
Seamonkey wird durch Entpacken des Tarball installiert (die Datei README enthält weitere Informationen). Das Directory kann eine beliebige Stelle im Dateisystem geschoben werden.
$ tar jxvf seamonkey-<VERSION>.tar.bz2 $ mkdir /usr/local/lib/seamonkey $ mv seamonkey /usr/local/lib/seamonkey/<VERSION>
Seamonkey starten
$ /usr/local/lib/seamonkey/<VERSION>/seamonkey
Mit der rechten Maustaste das Panel-Menü öffnen, "Add to panel" auswählen und einen "Custom Application Launcher" für das Executable anlegen. Das Seamonkey-Icon findet sich unter
seamonkey/<VERSION>/chrome/icons/default/default.png
![]()
Um per scp Dateien, die Whitespace im Dateienamen enthalten, von einem entfernten System zu kopieren, müssen die Leerzeichen zwei Mal maskiert werden: Einmal für die lokale Shell und einmal für die remote Shell.
Beispiel:
$ scp 'user@host:/pfad/"eine datei"' .
![]()
$ HandBrakeCLI --input=/dev/dvd --title=0 2>&1 | grep '\+'
[...]
+ title 3:
+ vts 1, ttn 3, cells 0->1 (150271 blocks)
+ duration: 00:14:27
+ size: 720x576, pixel aspect: 64/45, display aspect: 1.78, 25.000 fps
+ autocrop: 40/30/4/4
+ chapters:
+ 1: cells 0->0, 150266 blocks, duration 00:14:27
+ 2: cells 1->1, 5 blocks, duration 00:00:00
+ audio tracks:
+ 1, Deutsch (AC3) (2.0 ch) (iso639-2: deu), 48000Hz, 224000bps
+ subtitle tracks:
[...]
$ HandBrakeCLI --input=/dev/dvd --title=<n> --chapters=<k>[-<j>] \
--deinterlace --output=<name>.<ext>
Set video bitrate (default: 1000)
Language preference and default audio track.
Start encoding at a given frame, duration (in seconds), or pts (on a 90kHz clock)
Stop encoding at a given frame, duration (in seconds), or pts (on a 90kHz clock)
Set cropping values (default: autocrop)
Use two-pass mode
![]()
Der MySQL Query Optimizer kann bessere Query-Pläne generieren, wenn er Informationen über die Tabelleninhalte hat. Diese können per SQL mit ANALYZE TABLE erzeugt werden oder - einfacher - mit dem Kommandozeilenprogramm mysqlcheck. Die Option zum Analysieren heißt --analyze. Bei Angabe der Option --all-databases werden alle Tabellen aller Schemata (in MySQL-Sprechweise: Datenbanken) auf einen Schlag analysiert. Das ist meistens das, was man will.
$ mysqlcheck --analyze --all-databases ...
bzw. in Kurzform
$ mysqlcheck -a -A ...
![]()
Damit der MySQL-Server mysqld TCP-Verbindungen annimmt, muss ihm in my.cnf im Abschnitt [mysqld] eine Bind-Adresse zugewiesen werden:
bind-address = <server-ip>
Falls vorhanden, muss die Direktive skip-networking gleichzeitig auskommentiert werden, da diese Priorität hat und forciert, dass der Server nur Unix Domain Sockets zulässt.
Per SQL einen neuen User anlegen und ihm den Remote-Zugriff von allen Hosts ('%') auf alle Schemata und Tabellen (*.*) erlauben:
CREATE USER <user> IDENTIFIED BY '<password>'; GRANT ALL ON *.* TO '<user>'@'%';
Login mit mysql-Client:
$ mysql -u <user> -h <host> --password=<password>
Die User-Zugriffsberechtigungen stehen in der Tabelle mysql.user. Diese Tabelle kann mit INSERT/UPDATE/DELETE Statements auch direkt manipuliert werden.
![]()
$ ffplay INFILE -loop N
Wiederholt den Film N mal, 0 = unendlich oft. Wichtig: die Option muss nach INFILE stehen.
$ ffplay INFILE -vf scale=WIDTH:HEIGHT
Der Film wird in der Größe WIDTHxHIGH wiedergegeben.
Ändere die Größe eines Films in WIDTHxHEIGHT:
$ ffmpeg -i INFILE -s WIDTHxHEIGHT ... OUTFILE -s WIDTHxHEIGHT : die neue Breite und Höhe des Films
Die Option -s ist nur sinnvoll, wenn das Seitenverhältnis gleich bleibt. Ansonsten wird das Bild verzerrt. Bei abweichendem Seitenverhältnis kann mit den Operationen pad oder crop gearbeitet werden (siehe pad und crop).
$ ffmpeg -i INFILE -ss 0:0:12.200 -t 0:0:5 -codec copy OUTFILE -ss 0:0:12.200 : Start bei 12 Sekunden und 200 Millisekunden -t 0:0:5 : Länge 5 Sekunden (kann auch als -t 5 angegeben werden) -codec copy : Kopiere alle Streams ohne Reencoding.
Es ist wichtig, dass der Zeit-Offset -ss 0:0:12.200 als Parameter der Ausgabedatei angegeben wird, und nicht als Parameter der Eingabedatei, da sonst Keyframe-Probleme auftreten können.
Subtitle-Streams werden von -codec copy nicht kopiert (Bug?).
INFILE sei ein 16:9-formatiger Film der Größe 640x360, der mit 60 Pixel hohen Balken oben und unten auf 4:3-Format gebracht werden soll. Kommando:
$ ffmpeg -i INFILE -vf pad=640:480:0:60 ... OUTFILE pad : Operation: Auffüllen 640:480 : die Größe (Dimension) WIDTH:HEIGHT des Resultats (OUTFILE) 0:60 : der Offset X:Y des Films von der oberen linken Ecke des Resultats
Mit folgendem Kommando werden die Balken wieder entfernt.
$ ffmpeg -i INFILE -vf crop=640:360:0:60 ... OUTFILE
crop : Operation: Ausschneiden
640:360 : die Größe (Dimension) WIDTH:HEIGHT des Resultats
0:60 : der Offset X:Y des Ausschnitts von der oberen linken Ecke
des Eingangsmaterials (INFILE)
$ ffmpeg -i INFILE -ab 128k -acodec libmp3lame -ac 2 ... OUTFILE -ab 128k : Audio-Bitrate in kb/s -acodec libmp3lame : MP3 Codec -ac 2 : Zwei Kanäle (stereo)
$ ffmpeg -i INFILE -an ... OUTFILE
$ ffmpeg -i INFILE -b 5000k -r 25 -s 1280x720 ... OUTFILE -b 5000k : Video-Bitrate auf 5000 kb/s reduzieren -r 25 : Frame-Rate auf 25 Bilder pro Sekunde reduzieren -s 1280x720 : Bildauflösung auf 1280x720 Pixel reduzieren
![]()
Wenn serverseitig kein Zugriff auf die Header der HTTP-Antwort besteht, kann ein Cookie auch per HTML gesetzt werden:
| 1 | <script type="text/javascript"> |
| 2 | document.cookie = "KEY=VALUE"; |
| 3 | </script> |
Ein onchange-Handler setzt einen Cookie, der den Zustand eines Select-Menü anwendungsglobal speichert (Perl/CGI.pm):
| 1 | my $n = $cgi->cookie('n') || 25; |
| 2 | my $nSelect = $cgi->popup_menu( |
| 3 | -name=>'n', |
| 4 | -values=>[qw/1 2 5 10 15 20 25 30 40 50 75 100/], |
| 5 | -default=>$n, |
| 6 | -onChange=>'document.cookie = '. |
| 7 | '"n="+this.options[this.selectedIndex].value', |
| 8 | ); |
![]()
Oracle kennt die Pseudo-Kolumne ROWNUM, die die Datensätze einer Selektion von 1 an aufsteigend durchnummeriert. In MySQL existiert dieses Konzept nicht, es kann aber mittels einer Benutzer-definierten Variable simuliert werden.
Implementierung:
| 1 | SELECT |
| 2 | @rownum := @rownum + 1 ROWNUM |
| 3 | , t.* |
| 4 | FROM |
| 5 | (SELECT @rownum := 0) r, |
| 6 | t |
Einschränkung: Die Lösung ist unzureichend, wenn ein ORDER BY verwendet wird, da die Nummerierung vor der Sortierung stattfindet.
Unter Oracle wird ROWNUM auch benutzt, um die Ergebnismenge auf die ersten n Datensätze zu begrenzen. Dafür hat MySQL ein besseres Konzept, die SELECT-Klausel LIMIT.
![]()
Ein HTML-Formular soll mittels Abbruch-Button beendet werden, d.h. der Button soll die Formulardaten nicht abschicken, sondern auf eine andere Seite URL verzweigen, z.B. die Seite, von der aus das Formular aufgerufen wurde.
Implementierung:
<input type="button" value="Abbrechen" onclick="location.href = 'URL'">
Der Button ist ein einfacher Button (type="button"), kein Submit-Button, d.h. eine Formularaction wird durch den Button nicht ausgelöst.
Die Folgeseite URL wird durch Zuweisung an das href-Attribut des location-Objekts geladen.
![]()
Apache2::Reload ist ein Perl-Modul, das Module einer mod_perl-Applikation automatisch neu lädt, wenn diese geändert wurden. Andernfalls müsste der HTTP-Server neu gestartet werden um die Änderungen sichtbar zu machen, was während der Entwicklung umständlich ist und Zeit kostet.
Apache2::Reload von CPAN herunterladen
Apache Libs und Headerfiles installieren (Redhat-System)
yum install httpd-devel.x86_64
Modul installieren
perl Makefile.PL make make install
(make test geht nicht ohne Apache Testumgebung)
HTTP-Config ergänzen:
PerlModule Apache2::Reload PerlInitHandler Apache2::Reload
Apache neu starten
apachectl restart
![]()
Die Browser benutzen unterschiedliche Wege, Listen einzurücken. Einige rücken per Padding ein, andere per Margin.
Soll die Einrückung portabel verändert werden, müssen margin-left uns padding-left also zusammen gesetzt werden, und zwar eine Angabe auf die gewünschte Einrückung und die andere auf 0.
| 1 | ul { |
| 2 | padding-left: 20px; |
| 3 | margin-left: 0; |
| 4 | } |
oder
| 1 | ul { |
| 2 | padding-left: 0; |
| 3 | margin-left: 20px; |
| 4 | } |
![]()
Ein aus mehreren Elementen bestehendes HTML-Konstrukt soll in seinem Aussehen frei gestaltbar sein. Wie lässt sich dies mit CSS erreichen?
Gegeben sei ein Inhaltsverzeichnis, bestehend aus einer Überschrift (h1) und verschachtelten Listen (ul, li) mit Links (a) auf die Dokument-Abschnitte.
| 1 | <h1>Title</h1> |
| 2 | <ul> |
| 3 | <li> |
| 4 | <a href="#section_1">Section 1</a> |
| 5 | <ul> |
| 6 | <li> |
| 7 | <a href="#section_1_1">Section 1.1</a> |
| 8 | <ul> |
| 9 | <li> |
| 10 | <a href="#section_1_1_1">Section 1.1.1</a> |
| 11 | </li> |
| 12 | <li> |
| 13 | <a href="#section_1_1_2">Section 1.1.2</a> |
| 14 | </li> |
| 15 | </ul> |
| 16 | </li> |
| 17 | <li> |
| 18 | <a href="#section_1_2">Section 1.2</a> |
| 19 | </li> |
| 20 | </ul> |
| 21 | </li> |
| 22 | <li> |
| 23 | <a href="#section_2">Section 2</a> |
| 24 | </li> |
| 25 | </ul> |
Der HTML-Code wird ohne CSS vom Browser (Firefox) ungefähr so dargestellt (die Strukturelemente für den Titel (h1) und die Listen (ul) sind zur Verdeutlichung grau hinterlegt):

Um ein HTML-Konstrukt aus mehreren Elementen per CSS anpassbar zu machen, gehen wir folgendermaßen vor:
Wir geben dem Wurzelelement des Konstruktes eine eindeutige Bezeichnung und weisen ihm hierzu eine Id oder einen Klassennamen (oder beides) zu.
| 1 | <ELEMENT id="my-toc-4711" class="my-toc"> |
| 2 | ... |
| 3 | </ELEMENT> |
Eine Id verwenden wir, wenn wir eine bestimmte Instanz des Konstrukts gestalten wollen. Wollen wir alle Instanzen des Konstruktes gestalten, verwenden wir einen Klassennamen.
Hat das Konstrukt kein Wurzelelement, wie im Beispiel, denn auf oberster Ebene stehen hier zwei Elemente: h1 und ul, erzeugen wir ein künstliches Wurzelelement, indem wir das Konstrukt in ein <div> einfassen.
| 1 | <div class="my-toc"> |
| 2 | HTML |
| 3 | </div> |
Ein Wurzelelement zu haben, ist in vielerlei Hinsicht praktisch, denn es kann Definitionen aufnehmen, die das Konstrukt als Ganzes (Hintergrund, Abstände, etc.) oder alle seine Subelemente betreffen (Texteigenschaften etc.).
Im Stylesheet adressieren wir die Elemente ausgehend vom Wurzelelement mit entsprechenden Selektoren. Bei obiger Inhaltsverzeichnis-Struktur könnte dies so aussehen:
| 1 | .my-toc { |
| 2 | /* das gesamte Konstrukt */ |
| 3 | } |
| 4 | .my-toc h1 { |
| 5 | /* die Überschrift */ |
| 6 | } |
| 7 | .my-toc ul { |
| 8 | /* die Liste der Ebene 1 */ |
| 9 | } |
| 10 | .my-toc ul ul { |
| 11 | /* die Listen der Ebene 2 */ |
| 12 | } |
| 13 | .my-toc ul ul ul { |
| 14 | /* die Listen der Ebene 3 und tiefer */ |
| 15 | } |
| 16 | .my-toc a { |
| 17 | /* alle Links */ |
| 18 | } |
Weitere Klassennamen oder Ids werden innerhalb des Konstruktes nicht benötigt, es sei denn, es liegt der eher seltene Fall vor, dass CSS-Selektoren die erforderliche Elementauswahl nicht treffen können. Beispiel: gerade oder ungerade Zeilen einer Tabelle.
![]()
Mit dvgrab wird ein Video von einem digitalen Camcorder über FireWire gelesen und in Form von einzelnen Clips (.dv-Dateien) auf die Platte geschrieben. Die von mir bevorzugt verwendete Kommandozeile lautet:
$ dvgrab -autosplit -size 0 -timestamp clip- -autosplit : trenne den Video-Strom auf Clip-Grenzen -size 0 : erlaube, dass Clip-Dateien beliebig groß werden können -timestamp : füge den Timecode des ersten Frame zum Clip-Grundnamen hinzu clip- : Grundname der Clip-Dateien
Die Clip-Dateien erhalten die Namen clip-YYYY.MM.DD_HH-MI-SS.dv. Pro Sekunde fallen 3.43 MB an Daten an, eine Stunde Videomaterial belegt 12.35 GB Plattenplatz.
![]()
Das Core-Modul Pod::Usage kann einen Programm-Hilfetext aus der eingebetteten POD-Dokumentation generieren. Es geht auch einfacher:
| 1 | #!/usr/bin/env perl |
| 2 | |
| 3 | use strict; |
| 4 | use warnings; |
| 5 | |
| 6 | =head1 NAME |
| 7 | |
| 8 | myprog - a simple program |
| 9 | |
| 10 | =head1 LICENSE |
| 11 | |
| 12 | This program is free software; you can redistribute it and/or |
| 13 | modify it under the same terms as Perl itself. |
| 14 | |
| 15 | =cut |
| 16 | |
| 17 | exec 'pod2text',$0; |
| 18 | |
| 19 | # eof |
produziert auf STDOUT
NAME
myprog - a simple program
LICENSE
This program is free software; you can redistribute it and/or modify it
under the same terms as Perl itself.

Der Medion Life S60003 ist ein einfacher Player zum Abspielen von MP3- und WMA-Dateien.
Zum Datenaustausch wird dieser auf einen freien USB-Port gesteckt. Der Player wechselt in den Zustand "USB Connected". Wird gerade ein Titel gespielt, muss die Wiedergabe erst angehalten werden.
Der Player wird von udev erkannt und vom System automatisch auf ein Verzeichnis unter /media gemountet. Der Vorgang wird in /var/log/messages protokolliert:
usb 3-1: new high speed USB device using ehci_hcd and address 18 usb 3-1: New USB device found, idVendor=066f, idProduct=8588 usb 3-1: New USB device strings: Mfr=1, Product=2, SerialNumber=5 usb 3-1: Product: MD 83366 usb 3-1: Manufacturer: Medion usb 3-1: SerialNumber: 43F9000056B398A30002D8F515A958A3 usb 3-1: configuration #1 chosen from 1 choice scsi18 : SCSI emulation for USB Mass Storage devices scsi 18:0:0:0: Direct-Access Medion MD 83366 0100 PQ: 0 ANSI: 4 scsi 18:0:0:1: Direct-Access Medion MD 83366 0100 PQ: 0 ANSI: 4 sd 18:0:0:0: [sdc] 478976 4096-byte logical blocks: (1.96 GB/1.82 GiB) sd 18:0:0:0: [sdc] Write Protect is off sd 18:0:0:0: [sdc] 478976 4096-byte logical blocks: (1.96 GB/1.82 GiB) sd 18:0:0:1: [sdd] Attached SCSI removable disk sdc: sd 18:0:0:0: [sdc] 478976 4096-byte logical blocks: (1.96 GB/1.82 GiB) sd 18:0:0:0: [sdc] Attached SCSI removable disk
Der Mountpoint lässt sich mit mount(1) herausfinden:
$ mount ... /dev/sdc on /media/87C9-FFD0 type vfat (rw,nosuid,nodev,uhelper=udisks, uid=1000,gid=1000,shortname=mixed,dmask=0077,utf8=1,flush)
Eigentlich ist der Flash-Speicher des Players nicht direkt mountbar. Vielmehr wird der Player als MTP-Gerät (http://de.wikipedia.org/wiki/Media_Transfer_Protocol) angesprochen. Der Eintrag in /lib/udev/rules.d/45-libmtp8.rules lautet:
# Medion MD8333
ATTR{idVendor}=="066f", ATTR{idProduct}=="8588", SYMLINK+="libmtp-%k",
MODE="660", GROUP="audio"
Der Player kann, wenn obiges Setup stimmt, auch per Hand gemountet werden:
# mount /dev/sdX /mnt
X ist der Buchstabe des SCSI-Geräts ohne eine Partitionsnummer, hier: /dev/sdc.
Ist unter System/Preferences/File Management/Media (Gnome) die Option "Browse Media when inserted" aktiviert, wird von Gnome der File Browser Nautilus auf dem Verzeichnis gestartet, wenn es automatisch gemountet wird.
Aber ACHTUNG: Dies alles klappt nicht, wenn der Gnome Audio-Player Rhythmbox läuft! Dieser nimmt selbst mit dem Player via MTP Kontakt auf. Offenbar kann der Player nicht gleichzeitig gemountet sein, d.h. ein etwaiger Mount - egal ob automatisch oder manuell aufgebaut - wird sofort wieder abgebaut oder anderweitig gestört.
Gemountet kann der Player als Datenträger für beliebige Dateien und Verzeichnisstrukturen verwendet werden.
Auch die Musiksammlung kann theoretisch mittels Dateisystem-Operationen auf dem Player verwaltet werden. Dies ist allerdings nicht praktikabel, da der Player die in den MP3-Dateien enthaltenen ID3-Tags nicht auswertet. Werden MP3-Dateien einfach nur kopiert, befinden sie sich anschließend zwar auf dem Player und können gespielt werden, aber der Player "weiß" nichts über ihren Inhalt und kann dem Benutzer die zur Unterscheidung wichtigen Informationen Titel, Künstler, Album, Jahr, Genre nicht präsentieren.
Daher ist es besser, die Dateien mit Rhythmbox - oder einem anderen Programm, welches Musikdateien per MTP verwaltet - zu übertragen. Der Player erhält dann auch die Meta-Information zu den Dateien.
![]()
Perl kennt mehrere Zeichenketten, die - numerisch interpretiert - plus und minus Unendlich bedeuten.
| Plus Unendlich: | '+inf', '+infinity', 'inf', 'infinity' |
| Minus Unendlich: | '-inf', '-infinity' |
Beispiel: Maximum ermitteln
| 1 | my $max = '-inf'; |
| 2 | for my $n (-100,-10,-50) { |
| 3 | $max = $n if $n > $max; |
| 4 | } |
| 5 | say $max; |
| 6 | __END__ |
| 7 | -10 |
Aber Achtung: Diese besonderen Werte sind nicht sonderlich gut dokumentiert und scheinen bei einigen Windows-Ports nicht zu funktionieren. Siehe: Unendliches Perl...
![]()
Analog zu lexikalischen Filehandles besitzt Perl lexikalische Dirhandles. Eine Dirhandle ist ein Iterator über einem Verzeichnis. Die Operationen auf Dirhandles lassen sich objektorientiert kapseln.
Hier eine entsprechende Klasse Dirhandle mit drei Methoden: new() (Directory öffnen), close() (Directory schließen) und next() (nächster Directory-Eintrag):
| 1 | package Dirhandle; |
| 2 | |
| 3 | use strict; |
| 4 | use warnings; |
| 5 | |
| 6 | sub new { |
| 7 | my ($class,$dir) = @_; |
| 8 | |
| 9 | opendir my $dh,$dir or die "ERROR: opendir failed: $dir ($!)\n"; |
| 10 | return bless $dh,$class; |
| 11 | } |
| 12 | |
| 13 | sub close { |
| 14 | my $self = shift; |
| 15 | |
| 16 | closedir $self or die "ERROR: closedir failed ($!)\n"; |
| 17 | return; |
| 18 | } |
| 19 | |
| 20 | sub next { |
| 21 | return readdir shift; |
| 22 | } |
| 23 | |
| 24 | 1; |
| 25 | |
| 26 | # eof |
Beispiel: Gib alle Einträge des Verzeichnisses $dir auf STDOUT aus
1 use Dirhandle; 2 3 my $dh = Dirhandle->new($dir); 4 while (my $entry = $dh->next) { 5 say $entry; 6 } 7 $dh->close;
Das Dirhandle-Objekt $dh kann wie jede normale Dirhandle an die Perl-Builtins readdir(), telldir(), seekdir(), rewinddir(), closedir() übergeben werden.
![]()
Mit lexikalischen Filehandles ist es in Perl leicht möglich, File-I/O objektorientiert zu kapseln. Hier zur Veranschaulichung eine Klasse Filehandle mit drei Methoden: new() (Datei öffnen), close() (Datei schließen) und slurp() (Datei komplett einlesen):
| 1 | package Filehandle; |
| 2 | |
| 3 | use strict; |
| 4 | use warnings; |
| 5 | |
| 6 | sub new { |
| 7 | my ($class,$mode,$file) = @_; |
| 8 | |
| 9 | open my $fh,$mode,$file or die "ERROR: open failed: $file ($!)\n"; |
| 10 | return bless $fh,$class; |
| 11 | } |
| 12 | |
| 13 | sub close { |
| 14 | my $self = shift; |
| 15 | |
| 16 | close $self or die "ERROR: close failed ($!)\n"; |
| 17 | return; |
| 18 | } |
| 19 | |
| 20 | sub slurp { |
| 21 | my $self = shift; |
| 22 | |
| 23 | local $/; |
| 24 | return scalar <$self>; |
| 25 | } |
| 26 | |
| 27 | 1; |
| 28 | |
| 29 | # eof |
Beispiel: Lies eine Datei komplett ein und gib sie auf STDOUT aus
1 use Filehandle; 2 3 my $fh = Filehandle->new('<',$file); 4 print $fh->slurp; 5 $fh->close;
Der Clou: Die Filehandle $fh kann unabhängig von der Klasse wie jede andere Perl-Filehandle benutzt werden, z.B. mit dem Diamant-Operator <> oder jeder anderen Filehandle-Operation wie read(), write() usw. Obiges Programm lässt sich also auch so implementieren:
1 use Filehandle; 2 3 my $fh = Filehandle->new('<',$file); 4 while (<$fh>) { 5 print; 6 } 7 $fh->close;
![]()
Ich weiß nicht, wann Perl mir mal abgestürzt ist, aber jetzt bin ich auf einen Fall gestoßen:
| 1 | #!/usr/bin/env perl |
| 2 | |
| 3 | use strict; |
| 4 | use warnings; |
| 5 | |
| 6 | my $s; |
| 7 | close STDERR; |
| 8 | open STDERR,'>',\$s or die; |
| 9 | warn "a\n"; |
| 10 | $s =~ s/./xx/g; |
| 11 | |
| 12 | # eof |
Aufruf:
$ ./test.pl Segmentation fault
Perl-Version (andere habe ich nicht probiert):
$ perl -v This is perl, v5.10.1 (*) built for i686-linux
Wenn $s kein In-Memory File ist, geht es.
Bei $s =~ s/./xx/; geht es (ohne g Modifier).
Bei $s =~ s/./x/g; geht es (der String wird nicht länger).
Schließen von STDERR vor dem s/// ändert nichts.
![]()
Mitunter soll eine Menge von Dateien, die man erstellt und bearbeitet, systematisch in etwas anderes, z.B. ein anderes Format, konvertiert werden. Die Konvertierung lässt sich mit dem Utilty make organisieren, so dass überflüssige Konvertierungen vermieden werden.
Wie sieht ein GNU Makefile für diese Aufgabe aus?
Das folgende (fiktive) Beispiel geht davon aus, dass wir .in-Dateien in .out-Dateien konvertieren wollen. Die Konvertierung übernimmt das (fiktive) Programm in2out.
| 1 | OUTFILES = $(patsubst %.in,%.out,$(wildcard *.in)) |
| 2 | |
| 3 | %.out: %.in |
| 4 | in2out $< $*.out |
| 5 | |
| 6 | all: $(OUTFILES) |
| 7 | |
| 8 | clean: |
| 9 | rm -f *.out |
Definition der Liste der Targets, also der Dateien, die zu generieren sind. Das sind .out-Dateien. Diese Liste könnten wir per Hand pflegen, was aber mühselig wäre. Stattdessen nutzen wir die Möglichkeiten von GNU make und generieren die Liste mittels der Funktionen wildcard und patsub aus den im aktuellen Verzeichnis befindlichen .in-Quell-Dateien.
Pattern Rule, welche definiert, welche Kommandofolge aus einer .in-Quelldatei eine .out-Zieldatei erzeugt. Hier ist es ein einzelnes Kommando, der Aufruf von in2out [infile] [outfile]. Die make-Variable $< enthält den Namen der .in-Quelldatei, die Variable $* den Grundnamen der Quelldatei, aus dem durch Anhängen von ".out" der Name der Zieldatei wird.
Regel, die bei Aufruf von
$ make
oder
$ make all
zu erfüllen versucht wird. Diese (PHONY-)regel besagt, dass als Vorbedingung alle $(OUTFILES) zu generieren sind.
Regel ohne Vorbedingung, die aufräumt, also alle .out-Dateien löscht, z.B. um sie insgesamt neu zu generieren. Aufruf:
$ make clean
![]()
Highlight stellt die Syntax von zahlreichen Programmiersprachen farbig und mit Fontattributen wie kursiv und fett dar:
$ highlight --syntax=LANG --fragment <CODE >CODE.html
Die Option --syntax=LANG stellt die Programmiersprache ein, --fragment sorgt dafür, dass keine vollständige HTML-Seite, sondern einbettbarer HTML-Code generiert wird.
Die zugehörigen CSS-Klassen liefert folgendes Kommando nach stdout:
$ highlight --print-style --style-outfile=stdout | grep '^\.' >CODE.css
Das nachgeschaltete grep sorgt dafür, dass der Output auf die relevanten Klassen für eine Einbettung eingeschränkt wird.
![]()
Pertidy stellt die Syntax von Perl-Code farbig und mit Fontattributen wie kursiv und fett dar, wenn man den Code mit Option -html nach HTML wandelt. Ich nutze dieses Feature, um gut lesbareren Perl-Code für mein Blog zu generieren.
Für die Einbettung des generierten HTML-Codes in eigene HTML-Seiten sind allerdings kleinere Sonderbehandlungen nötig.
Perltidy generiert mit
$ perltidy -html -ss >FILE.css
eine Stylesheet-Datei, die die Definitionen der CSS-Klassen für die Syntaxelemente enthält und in die eigenen HTML-Seiten eingebunden werden kann:
Command failed: ./blog-highlight CSS ehtml
Die CSS-Definitionen für <body> und <pre> am Anfang sollten im Falle einer Einbettung nicht vorkommen, da diese an anderer Stelle definiert sind. Sie lassen sich mit grep wegfiltern.
$ perltidy -html -ss | grep '^\.'
Die Namen der CSS-Klassen bestehen aus ein oder zwei Buchstaben, was zu Nameclashes führen kann. Dies verbessere ich, indem ich dem Klassennamen einen Präfix voranstelle. Ich wähle "pt-".
$ perltidy -html -ss | grep '^\.' | sed -e 's/^\./.pt-/'
Command failed: ./blog-highlight CSS ehtml
Perltidy erzeugt mit
$ perltidy -html -pre <FILE >FILE.html
eine Quelltext-Darstellung in HTML. Diese kann in die eigene Seite eingebunden werden.
Der HTML-Code ist in ein <pre> ohne CSS-Klassenangabe eingefasst. Das CSS-Layout dieses <pre> lässt sich also nicht gezielt anpassen. Am besten filtert man es weg und setzt den HTML-Code in ein eigenes <pre>.
$ perltidy -html -pre <FILE | egrep -v '^</?pre>'
Die CSS-Klassennamen müssen an die oben gewählten Namen in der Stylesheet-Datei angepasst werden.
$ perltidy -html -pre | egrep -v '^</?pre>' | sed -e 's/class="/class="pt-/g'
Aus
print "Hello world!\n";
wird im HTML-Output (Umbruch hinzugefügt)
<span class="pt-k">print</span> <span class="pt-q"> "Hello world!\n"</span><span class="pt-sc">;</span>
und im Browser
print "Hello world!\n";
![]()
Ist eine FAQ (s. perldoc -q occurrences), aber ich vergesse immer die genaue Syntax, da ich tr/// selten nutze und es mehrere Funktionen in sich vereint:
$n = $str =~ tr/\n//;
$n ist in diesem Fall die Anzahl der Zeilenumbrüche in $str.
![]()
Mit der Option -a führt rsync den Abgleich im "Archive Mode" durch, d.h. Symlinks, Devices, Permissions, Ownerschaft usw. werden auf die Zielmaschine transferiert.
Was aber, wenn gewisse Unterschiede erforderlich sind, z.B. die Ownerschaft einiger Dateien verschieden sein muss, weil der Owner oder die Group auf der Zielmaschine anders heißen?
Beispiel: Die Group des HTTP-Servers heißt auf der einen Maschine "www-data" während sie auf der anderen Maschine "apache" heißt. Über die Group bekommt der HTTP-Server Rechte auf bestimmten Dateien eingeräumt, sie muss also passend zur Maschine gesetzt sein.
Solche Differenzen kann rsync nicht auflösen und bietet auch keine Option hierfür. Es lässt sich aber mit einem nachgeschalteten Shell-Skript erreichen, das via ssh auf der Zielmaschine ausgeführt wird:
rsync -avz --delete -e ssh DIR1/ USER@HOST:DIR2 ssh USER@HOST CMD
Wird CMD in DIR1 abgelegt, wird es durch den rsync-Aufruf mit verwaltet, also automatisch auf dem neusten Stand gehalten.
![]()
Statt den Mailto-URL per href zu setzen, wird der mailto-URL zum Zeitpunkt des Klicks via JavaScript generiert.
Nicht gut:
<a href="mailto:rudi.ratlos@host.dom">...</a>
Besser:
<a href="#" onclick="this.href = 'mailto:rudi.ratlos'+'@'+'host.dom'">...<a/>
Dies setzt natürlich JavaScript voraus. Aber schreibt heutzutage noch jemand Web-Anwendungen ohne JavaScript?
Statt die Email-Adresse im Klartext hinzuschreiben, wird das @-Zeichen ausgetauscht: entweder durch ein HTML-Entity, eine Zeichenkette wie "<AT>" oder eine Grafik:
Nicht gut:
rudi.ratlos@host.dom
Besser:
rudi.ratlos@host.dom
Noch besser, mit Text:
rudi.ratlos<AT>host.dom
Mit Grafik:
rudi.ratlos<img src="at.png" alt="AT" ... />host.dom
Bei einer Grafik besteht lediglich das Problem, dass diese vom Aussehen statisch ist, das Aussehen des umgebenden Textes u.U. nicht immer gleich ist, z.B. in unterschiedlichen Browsern oder durch Farbänderung beim Überfahren eines Link.
![]()
Vielleicht trivial, aber mir war die Antwort bislang nicht klar: Wie gebe ich eine Gleitkomma-Zahl aus, ohne dass Stellen wegfallen oder überflüssige Nullen am Ende erscheinen?
Bei der Ausgabe von Gleitkommazahlen habe ich bislang automatisch zu printf/sprintf und %f gegriffen, aber das Format-Element %f formatiert die Zahlen ja immer auf eine feste Anzahl an Stellen und rundet auf die letzte Stelle. Z.B.
my $x = 0.123456789; printf "%f",$x;
ergibt
0.123457
(%f formatiert/rundet per Default auf 6 Nachkommastellen)
Natürlich kann ich die Anzahl der Stellen groß wählen, aber dann bekomme ich u.U. zusätzliche Stellen, wenn die betreffende Zahl binär nur näherungsweise dargestellt werden kann:
my $x = 0.123456789; printf "%.20f",$x;
ergibt
0.12345678899999999734
Andererseits erhalte ich am Ende überflüssige Nullen bei Zahlen, die dezimal weniger als die vorgegebenen Stellen besitzen:
my $x = 0.5; printf "%.20f",$x;
ergibt
0.50000000000000000000
Was tun?
Die Lösung ist (anscheinend) einfach: Ich gebe die Zahl nicht als Zahl sondern als String aus! D.h. im Falle von printf/sprintf mit Format-Element %s!
Damit erhalte ich, was ich will. Die Zahl mit allen Stellen und nicht mehr
my $x = 0.123456789; printf "%s",$x; -> 0.123456789
und ohne überflüssige Nullen
my $x = 0.5; printf "%s",$x; -> 0.5
Bei näherer Überlegung leuchtet das ein, da Perl intern neben der (binären) numerischen Repräsentation eine Stringrepräsentation des Werts speichert, welche anfänglich genau der Zeichenfolge bei der Zuweisung entspricht.
Schlussfolgerung: Programme, die nicht rechnen, sondern Gleitkommazahlen nur einlesen und wieder ausgeben, sollten, um Verfälschungen auszuschließen, diese bei der Ausgabe grundsätzlich als Strings und nicht als Zahlen behandeln.
![]()
Eine einfache (eventuell nicht besonders wirksame) Methode, um Email-Adressen in HTML-Seiten unkenntlich zu machen, um sie vor Spammern zu verbergen, ist, sie in Entity-Schreibweise zu wandeln. Der folgende Perl-Code wandelt einen beliebigen String in Entity-Schreibweise:
| 1 | while ($str =~ /(.)/g) { |
| 2 | printf '&#%d;',ord $1; |
| 3 | } |
Beispiel:
$ ./str-to-entity 'rudi.ratlos@...'
rudi.ratlos
@...
![]()
$ echo "ServerAliveInterval 120" >> /etc/ssh/ssh_config
Wenn der Server 120 Sekunden kein Paket gesendet hat, sendet der Client ein Dummy-Paket zum Server.
Bei Putty findet sich die Einstellung in den Einstellungen unter Connection / Seconds between keepalives.
$ echo "ClientAliveInterval 120" >> /etc/ssh/sshd_config $ /etc/init.d/ssh reload
Wenn der Client 120 Sekunden kein Paket gesendet hat, sendet der Server ein Dummy-Paket zum Client.
![]()
Ein automatisches Login führt SSH durch, wenn auf der Zielmaschine der Öffentliche Schlüssel des eigenen Accounts hinterlegt ist. Der Öffentliche Schlüssel wird auf der Zielmaschine zum Zielaccount hinzugefügt mittels:
$ cat id_rsa.pub >>.ssh/authorized_keys
Die Datei darf nur für den Owner schreibbar sein.
Information zur Schlüsselgenerierung: http://www.supportnet.de/faqsthread/806
![]()
Umwandlung eines TIMESTAMP WITHOUT TIME ZONE in Unix-Epoch (Sekunden seit 1.1.1970 0 Uhr) in einer Anwendung, die mit UTC-Zeiten arbeitet:
sql> SELECT EXTRACT(EPOCH FROM TIMESTAMP
'1970-01-01 00:00:00' AT TIME ZONE 'UTC') AS t;
t
---
0
Entscheidend ist hier der Zusatz "AT TIME ZONE 'UTC'", denn ein TIMESTAMP WITHOUT TIME ZONE wird als Zeit der lokalen Zeitzone interpretiert - nicht etwa UTC! Ohne den Zusatz ist das Resultat um dem Offset der lokalen Zeitzone verschoben - böse Falle. Hier das Ergebnis im Falle von MEZ (+0100):
sql> SELECT EXTRACT(EPOCH FROM TIMESTAMP '1970-01-01 00:00:00') AS t; t ------- -3600
EXTRACT(EPOCH FROM t) extrahiert die Epoch-Sekunden
vom Zeit-Wert C{t}.
TIMESTAMP '1970-01-01 00:00:00' ist die Zeitangabe t.
AT TIME ZONE 'UTC' interpretiert die Zeitangabe t hinsichtlich Zeitzone UTC.
Umwandlung von Epoch-Sekunden in einen TIMESTAMP WITHOUT TIMEZONE (die 0 steht für den Epoch-Wert):
sql> gkss=# SELECT TIMESTAMP 'epoch' + 0 * INTERVAL '1 second' AS t;
t
---------------------
1970-01-01 00:00:00
TIMESTAMP 'epoch' bzeichnet den Anfang der Zeitrechnung (1.1.1970 0 Uhr).
0 * INTERVAL '1 second' ist der Zeitoffset in Sekunden, der hinzuaddiert wird. Er kann auch negativ sein.
Das Resultat ist ein Timestamp.
![]()
$ rsync -avz --delete DIR1/ USER@HOST:DIR2
Der trailing Slash bei DIR1/ ist wichtig, da sonst DIR1 in dir DIR2 hineinkopiert wird. Die Verzeichnisse können unterschiedlich heißen.
Bei Angabe der Option -n wird die Ausführung nur simuliert.
$ rsync -e ssh -avz --delete DIR1/ USER@HOST:DIR2
$ rsync --rsh='ssh -p port' -avz --delete DIR1/ USER@HOST:DIR2
![]()
Für den Umgang mit Symlinks stellt Perl eine Reihe von Builtins zur Verfügung, die nicht unbedingt offensichtlich sind. Hier eine kurze Übersicht:
Test auf Symlink:
$bool = -l $path;
Dateisystem-Eigenschaften des Symlink:
@stat = lstat $path;
Ziel des Symlink:
$destPath = readlink $path;
Erstelle Symlink $path mit Ziel $destPath, liefert 0 im Fehlerfall:
$bool = symlink $path,$destPath;
![]()
Wie ermittele ich, welche Perl-Module über das Grundsystem hinaus installiert wurden?
Die Antwort liefert das Kommando:
$ perldoc perllocal
Das Ergebnis ist ein formatiertes POD-Dokument, das die Installationshistorie aller per make install oder ./Build install installierten Module aufführt.
Das Dokument wird mit der Installation des ersten Moduls angelegt. Unmittelbar nach Installation des Core-Systems ist es noch nicht vorhanden, da noch kein zusätzliches Modul installiert wurde.
Mit jeder Modul-Installation wird ein Eintrag am Ende hinzugefügt. Wird ein Modul mehrfach installiert, taucht es mehrfach auf.
Liefere die Namen der zusätzlich installierten Module, alphabetisch sortiert, ohne Dubletten:
1 #!/usr/bin/env perl 2 3 use strict; 4 use warnings; 5 6 my %mod; 7 my $cmd = 'perldoc -u perllocal'; 8 open(my $fh,'-|',$cmd) or die "ERROR: open failed ($!)"; 9 while (<$fh>) { 10 if (/^=head2.*\|(.*)>/) { 11 $mod{$1} = 1; 12 } 13 } 14 close($fh) or die qq|ERROR: Command failed: "$cmd" (Exit Code: $?)\n|; 15 16 for my $mod (sort keys %mod) { 17 print "$mod\n"; 18 } 19 20 # eof
Sammlung von mehreren tausend qualitativ hochwertigen Desktop- und Web-Icons: http://www.iconarchive.com/
Fugue Icons: http://p.yusukekamiyamane.com/
![]()
iconv - Convert encoding of given files from one encoding to another
$ iconv -f ISO-8859-1 -t UTF-8 INPUT >OUTPUT
tcs - translate character sets
$ tcs -f 8859-1 INPUT >OUTPUT
![]()
Der Speicherbedarf von einzelnen Perl-Variablen und komplexeren Datenstrukturen lässt sich mit Devel::Size ermitteln. Hier die Werte für Perl 5.10 auf einem 32-Bit System.
(Eine andere Betrachtung - Messung des verbrauchten virtuellen Speichers bei großen Datenstrukturen - hat Peter J. Holzer angestellt: http://www.hjp.at/programming/perl/memory/)
| Skalar ohne Wert: | 16 Bytes |
|---|---|
| Referenz: | 16 Bytes |
| Integer: | 16 Bytes |
| Float: | 24 Bytes |
| Leerstring: | 36 Bytes |
| String der Länge n: | 36+n Bytes |
Perl alloziert bei Strings jeweils 4 Bytes im Voraus, vermutlich um jedes UTF-8 Zeichen speichern zu können. Obige Berechnung geht von 1-Byte-Zeichen aus. Enthält der String UTF-8 Zeichen mit 2, 3 oder 4 Byte, vergrößert sich der Platzbedarf entsprechend.
| leeres Array: | 100 Bytes |
|---|---|
| Array der Größe n: | 100+4*n Bytes |
Perl vergrößert ein Array schrittweise auf 4, 8, 16, 32, 64, ... Elemente. D.h. wird das 4. Element zugewiesen, vergößert Perl intern schon auf 8 Elemente usw. Für jedes Element alloziert Perl einen Pointer (4 Bytes). Die angegebene Größe ist der Netto-Speicherbedarf des Array, d.h. der Speicherbedarf der (skalaren) Werte kommt noch hinzu.
| leerer Hash: | 76 Bytes |
|---|---|
| Hash mit n Keys: | ungefähr 76+n*4+n*(durchschn. Keygröße+8+Anz. Buckets) |
Perl vergrößert einen Hash schrittweise auf 8, 16, 32, 64, ... Elemente. D.h. wird das 8. Element zugewiesen, vergößert Perl intern auf 16 Elemente usw. Für jeden Key alloziert Perl vorab einen Pointer (4 Bytes). Zusätzlich kommt mit zunehmender Anzahl Buckets ein wachsender Overhead von 9, 10, 11, ... Bytes je Key hinzu. Die Größe des Key geht auch mit ein. Bei der Messung unten ist der Key der String "EintragNNNN", also 11 Zeichen lang. Die angegebene Größe ist der Netto-Speicherbedarf des Hash, d.h. der Speicherbedarf der Werte kommt noch hinzu.
Perl Version: 5.026000 Skalar ohne Wert: 24 Bytes Referenz: 24 Bytes Integer: 24 Bytes Float: 24 Bytes String - leer: 42 Bytes String - 1 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 2 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 3 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 4 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 5 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 6 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 7 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 8 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 9 1-Byte Zeichen: 42 Bytes (Diff: 0) String - 10 1-Byte Zeichen: 48 Bytes (Diff: 6) String - 11 1-Byte Zeichen: 48 Bytes (Diff: 0) String - 12 1-Byte Zeichen: 48 Bytes (Diff: 0) String - 16 1-Byte Zeichen: 56 Bytes (Diff: 8) String - 20 1-Byte Zeichen: 56 Bytes (Diff: 0) Array - leer: 64 Bytes Array - 4 Elemente: 96 Bytes (Diff: 32) - 24.0 Bytes/Key Array - 8 Elemente: 128 Bytes (Diff: 32) - 16.0 Bytes/Key Array - 16 Elemente: 200 Bytes (Diff: 72) - 12.5 Bytes/Key Array - 32 Elemente: 344 Bytes (Diff: 144) - 10.8 Bytes/Key Array - 64 Elemente: 624 Bytes (Diff: 280) - 9.8 Bytes/Key Hash - leer: 120 Bytes Hash - 4 Keys: 396 Bytes (Diff: 276) - 99.0 Bytes/Key Hash - 8 Keys: 736 Bytes (Diff: 340) - 92.0 Bytes/Key Hash - 16 Keys: 1416 Bytes (Diff: 680) - 88.5 Bytes/Key Hash - 32 Keys: 2776 Bytes (Diff: 1360) - 86.8 Bytes/Key Hash - 64 Keys: 5496 Bytes (Diff: 2720) - 85.9 Bytes/Key Hash - 128 Keys: 10936 Bytes (Diff: 5440) - 85.4 Bytes/Key Hash - 256 Keys: 21872 Bytes (Diff: 10936) - 85.4 Bytes/Key Hash - 512 Keys: 43632 Bytes (Diff: 21760) - 85.2 Bytes/Key Hash - 1024 Keys: 87152 Bytes (Diff: 43520) - 85.1 Bytes/Key
1 #!/usr/bin/env perl 2 3 use strict; 4 use warnings; 5 6 use Devel::Size; 7 8 print "Perl Version: $]\n"; 9 10 my $s1; 11 print 'Skalar ohne Wert: ',Devel::Size::size(\$s1)," Bytes\n"; 12 13 my $s2 = \$s1; 14 print 'Referenz: ',Devel::Size::size(\$s2)," Bytes\n"; 15 16 my $s3 = 4711; 17 print 'Integer: ',Devel::Size::size(\$s3)," Bytes\n"; 18 19 my $s4 = 1234.567; 20 print 'Float: ',Devel::Size::size(\$s4)," Bytes\n"; 21 22 my $s5 = ''; 23 my $nLast = Devel::Size::size(\$s5); 24 print "String - leer: $nLast Bytes\n"; 25 26 for my $i (1..12,16,20) { 27 $s5 = 'x'x$i; 28 my $n = Devel::Size::size(\$s5); 29 print "String - $i 1-Byte Zeichen: $n Bytes (Diff: ",$n-$nLast,")\n"; 30 $nLast = $n; 31 } 32 33 my @a1; 34 $nLast = Devel::Size::size(\@a1); 35 print "Array - leer: $nLast Bytes\n"; 36 37 for my $i (4,8,16,32,64) { 38 my @a2 = (1..$i); 39 my $n = Devel::Size::size(\@a2); 40 my $diff = $n-$nLast; 41 my $avg = $n/$i; 42 printf "Array - $i Elemente: $n Bytes (Diff: $diff) - %.1f Bytes/Key\n", 43 $avg; 44 $nLast = $n; 45 } 46 47 my %h1; 48 $nLast = Devel::Size::size(\%h1); 49 print "Hash - leer: $nLast Bytes\n"; 50 51 for my $i (4,8,16,32,64,128,256,512,1024) { 52 my %h2; 53 for (my $j = 1; $j <= $i; $j++) { 54 $h2{sprintf 'Eintrag%04d',$j} = $j; 55 } 56 # @h2{(1..$i)} = (1..$i); 57 my $n = Devel::Size::size(\%h2); 58 my $diff = $n-$nLast; 59 my $avg = $n/$i; 60 printf "Hash - $i Keys: $n Bytes (Diff: $diff) - %.1f Bytes/Key\n",$avg; 61 $nLast = $n; 62 } 63 64 # eof
![]()
<input type="text" id="e" name="text" size="20" />
Rahmen von 1px Breite statt der normalen Dekoration.
#e {
border: 1px #999 solid;
}
Die Hintergrundfarbe des Eingabefeldes ändern, wenn es mit der Maus überfahren wird (:hover) oder den Fokus bekommt (:focus). Besitzt das Feld weder den Fokus noch befindet sich die Maus darüber, wird die ursprüngliche Hintergrundfarbe automatisch wieder hergestellt. Dies braucht nicht vereinbart werden.
#e:hover, #e:focus {
background-color: #eee;
}
Ein Text-Eingabefeld sollte m.E. normalerweise einen monospaced Font eingestellt haben, nur dann entspricht die optische Feldbreite exakt der Anzahl der Zeichen, die in das Feld passen.
#e {
font-family: monospace;
}
![]()
In HTML:
| 1 | <table cellspacing="0"> |
Per CSS (#t sei die Tabelle):
| 1 | #t { |
| 2 | border-collapse: collapse; |
| 3 | } |
| 4 | |
| 5 | #t > td { |
| 6 | padding: 0; |
| 7 | } |
![]()
Layout mit Kopf, Fuss und drei Spalten:

Der HTML- und CSS-Code, der dies realisiert:
<div id="header"> Header </div> <div id="left"> Left </div> <div id="right"> Right </div> <div id="middle"> Middle </div> <div id="footer"> Footer </div>
#header { clear: both; } #left { float: left; width: 80px; } #right { float: right; width: 80px; } #middle { padding: 0 80px 0 80px; } #footer { clear: both; }
Die Breite von #header, #middle und #footer passt sich dem zur Verfügung stehenden Raum dynamisch an.
Die Reihenfolge der divs in HTML ist signifikant. Das div #middle kommt nach #left und #right.
"clear: both;" bei #header bewirkt, dass neben dem Header kein Float platziert wird. D.h. die beiden Floats #left und #right werden vom Browser darunter platziert.
Durch "float: left;" wird das Element #left links platziert. Analog wird Element #right durch "float: right;" rechts platziert. Die Breitenangabe "width: 80px;" weist den Floats ihren (fixen) horizontalen Raum am linken und rechten Rand zu.
Das Element #middle hat keine clear-Angabe und kann daher zwischen die Elemente #left und #right treten. Damit der Inhalt des div sich nicht mit den Randelementen überschneidet, wird mit "padding: 0 80px 0 80px;" ein Padding eingestellt, das den Raum, der von den Randelementen belegt wird, ausspart. Die Reihenfolge der Angaben ist: oben, rechts, unten, links.
"clear: both;" bei #footer verhindert, dass beim horizontalen Verkleinern des Fensters die oberen Floats neben oder unter den Footer springen.
Die Konstruktion aus den fünf divs kann in den HTML <body> oder eine Tabellenzelle <td> eigebettet werden.
Das W3C stellt zwei Services zur Validierung von HTML- und CSS-Code zur Verfügung:
Um den HTML- bzw. CSS-Code einer Seite direkt zu validieren, können folgende Links in die Seite eingebaut werden. Aus dem Referer-Header ermittelt der Validator die Ausgangsseite und ruft diese ab. Das geht natürlich nur, wenn die Seite öffentlich zugreifbar ist.
![]()
<a href="http://validator.w3.org/check/referer?ss=1"> <img src="valid-xhtml10.png" width="88" height="31" alt="Valid XHTML 1.0!" /> </a>
Der URL-Parameter ss=1 sorgt dafür, dass der Validator ein Source-Listing erzeugt. Dies ist sehr sinnvoll, da dann von einem Fehler aus direkt an die beanstandete Stelle gesprungen werden kann.
![]()
<a href="http://jigsaw.w3.org/css-validator/check/referer"> <img src="valid-css2.png" width="88" height="31" alt="Valid CSS!" /> </a>
![]()
Zu Datei: templates/default/index.tpl
Zu index.php?/archives/summary.html in Datei: templates/default/index.tpl
![]()
Die Admin-Oberfläche bietet keine getrennte Einstellung für den eigenen Style - entweder der Haupt-Style ändert den Style der Admin-Oberfläche mit oder es bleibt bei dem (für meinen Geschmack) nicht sonderlich schönen Default.
Die Admin-Styles sind in den Verzeichnissen der Haupt-Styles in templates/STYLE/admin definiert. Die Haupt-Styles, die einen Admin-Style mitbringen, lassen sich folgendermaßen ermitteln:
$ find templates -type d | grep admin$ ./carl_contest/admin ./competition/admin ./contest/admin ./bulletproof/admin ./default-rtl/admin ./default/admin
Ein Style, der keinen Admin-Style definiert, kann mit einem fremden Admin-Style ausgestattet werden, indem ein fremdes admin Verzeichnis (eines anderen Style) dorthin kopiert wird oder ein Symlink auf dieses angelegt wird:
$ cd templates/MYSTYLE $ ln -s ../OTHERSTYLE/admin .
![]()
Mit folgender Shebang-Zeile wird der Perl-Interpreter über die Environment-Variable $PATH gesucht:
#!/usr/bin/env perl
D.h. die Shebang-Zeile muss nicht angepasst werden, wenn das Skript in mehreren Umgebungen mit unterschiedlichen Perl-Installationspfaden laufen soll.
![]()
Meine Wahl der Blog-Software ist auf Serendipity gefallen, da ich es neulich positiv erwähnt gefunden habe und meine anschließende Recherche ergeben hat, dass es wohl tatsächlich gut ist.
Als ersten technischen Eintrag schreibe ich auf, wie ich Serendipity from scratch auf meinem Debian Web-Host installiert habe. Zwar gibt es Serendipity auch fix und fertig als Debian-Paket, aber das ist in Debian/Stable schon älter. Außerdem ist diese Anwendung für mich wichtig genug, dass ich alles im Detail kontrollieren möchte, einschließlich programmierung, und keinesfalls will, dass die Debian-Paketverwaltung mir mit Updates dazwischen kommt.
Homepage von Serendipity: http://www.s9y.org/
Auf der Homepage bekommt man die aktuelle Version als Tarball und auch eine Beschreibung für die manuelle Installation. Diese hat den Titel Fresh Installation. Sie ist gut, aber in einigen Punkten nicht ausführlich genug. Ich beschreibe hier die Dinge, die ich bei meiner Installation dort nicht gefunden habe.
Das Paket, in meinen Fall serendipity-1.5.1.tar.gz, kann irgendwo im Dateisystem ausgepackt werden. In der Webserver-Konfiguration wird später mitgeteilt, wo es sich befindet. Ich entscheide mich als Installationsort für /opt/serendipity/1.5.1/.
# deb-install php5 # apt-get install postgresql # apt-get install php5-pgsql # apt-get install imagemagick
Serendipity ist in PHP5 programmiert. Als DBMS verwende ich PostgreSQL. Imagemagick wird von Serendipity zur Bildbearbeitung gebraucht.
Im Serendipity-Paket scheint keine Apache-Config dabei zu sein. Ich habe diese von der Debian-Version übernommen, mit der ich zuvor herumgespielt habe. Lediglich die Pfade brauchte ich anpassen. Der URL des Blog wird http://SERVER.DOMAIN/blog lauten.
Alias /blog /opt/serendipity/1.5.1
<Directory /opt/serendipity/1.5.1>
Options -Indexes +FollowSymlinks
DirectoryIndex index.php
<IfModule mod_php5.c>
php_flag session.use_trans_sid off
php_flag register_globals off
</IfModule>
AllowOverride All
order allow,deny
allow from all
<Files *.tpl.php>
deny from all
</Files>
<Files *.tpl>
deny from all
</Files>
<Files *.sql>
deny from all
</Files>
<Files *.inc.php>
deny from all
</Files>
<Files *.db>
deny from all
</Files>
</Directory>
Die Datei wird als serendiptiy.conf nach /etc/apacha2/conf.d kopiert und anschließend der Apache neu gestartet:
# apache2ctl restart
Für die Datenbank-Einrichtung sind drei Dinge zu tun:
1. Datenbank erzeugen 2. Datenbank-User erzeugen, über den Serendipity auf die Datenbank zugreift 3. Datenbanknamen und User und Passwort in die Serendipity-Config eintragen
Datenbank und User erzeugen:
# su - postgres $ createdb serendipity $ createuser -P serendipity Password:
Wichtig ist bei creatuser der Parameter -P, damit der User ein Passwort erhält.
Anschließend auf http://SERVER.DOMAIN/blog/serendipity_admin.php gehen und die Datenbank-Angaben in die Formularfelder eintragen
Bei Anmeldeaufforderung per "John Doe" mit Passwort "john" anmelden. Benutzername und Passwort sollten nach der Anmeldung als erstes geändert werden. Danach kann Serendipity im Detail den eigenen Wünschen angepasst werden.
Die Inhalte dieses Blog wurden mit größtmöglicher Sorgfalt und nach bestem Gewissen erstellt. Dennoch übernehme ich, Frank Seitz, im folgenden "Anbieter" genannt, keine Gewähr für die Aktualität, Vollständigkeit und Richtigkeit der bereitgestellten Seiten und Inhalte.
Als Diensteanbieter ist der Anbieter dieser Webseite gemäß § 7 Abs. 1 TMG für eigene Inhalte und bereitgestellte Informationen auf diesen Seiten nach den allgemeinen Gesetzen verantwortlich; nach den §§ 8 bis 10 TMG jedoch nicht verpflichtet, die übermittelten oder gespeicherten fremden Informationen zu überwachen. Eine Entfernung oder Sperrung dieser Inhalte erfolgt umgehend ab dem Zeitpunkt der Kenntnis einer konkreten Rechtsverletzung. Eine Haftung ist erst ab dem Zeitpunkt der Kenntniserlangung möglich.
Die Webseite enthält sog. "externe Links" (Verlinkungen) zu anderen Webseiten, auf deren Inhalt der Anbieter der Webseite keinen Einfluss hat. Aus diesem Grund kann der Anbieter für diese Inhalte auch keine Gewähr übernehmen. Für die Inhalte und Richtigkeit der bereitgestellten Informationen ist der jeweilige Anbieter der verlinkten Webseite verantwortlich. Zum Zeitpunkt der Verlinkung waren keine Rechtsverstöße erkennbar. Bei Bekanntwerden einer solchen Rechtsverletzung wird der Link umgehend entfernt.
Die auf dieser Webseite veröffentlichten Inhalte, Werke und bereitgestellten Informationen unterliegen dem deutschen Urheberrecht und Leistungsschutzrecht. Jede Art der Vervielfältigung, Bearbeitung, Verbreitung, Einspeicherung und jede Art der Verwertung außerhalb der Grenzen des Urheberrechts bedarf der vorherigen schriftlichen Zustimmung des jeweiligen Rechteinhabers. Das unerlaubte Kopieren/Speichern der bereitgestellten Informationen auf diesen Webseiten ist nicht gestattet und strafbar.
Durch den Besuch des Internetauftritts können Informationen (Datum, Uhrzeit, aufgerufene Seite) über den Zugriff auf dem Server gespeichert werden. Es werden keine personenbezogenenen (z. B. Name, Anschrift oder E-Mail-Adresse) Daten, gespeichert.
Sofern personenbezogene Daten erhoben werden, erfolgt dies, sofern möglich, nur mit dem vorherigen Einverständnis des Nutzers der Webseite. Eine Weitergabe der Daten an Dritte findet ohne ausdrückliche Zustimmung des Nutzers nicht statt.
Der Anbieter weist darauf hin, dass die Übertragung von Daten im Internet (z.B. per E-Mail) Sicherheitslücken aufweisen und ein lückenloser Schutz der Daten vor dem Zugriff Dritter nicht gewährleistet werden kann. Der Anbieter übernimmt keine Haftung für die durch solche Sicherheitslücken entstandenen Schäden.
Der Verwendung der Kontaktdaten durch Dritte zur gewerblichen Nutzung wird ausdrücklich widersprochen. Es sei denn, der Anbieter hat zuvor seine schriftliche Einwilligung erteilt. Der Anbieter behält sich rechtliche Schritte für den Fall der unverlangten Zusendung von Werbeinformationen, z. B. durch Spam-Mails, vor.
Ich habe beschlossen ein Technik-Blog zu führen, in dem ich meine Erfahrungen aufschreibe. Primär als Nachschlagewerk zur eigenen Erinnerung, aber auch als mögliche Hilfe für andere. Ich selbst schlage oft im Web nach, wenn ich auf eine Fragestellung oder ein Problem stoße, und meistens ist etwas darunter was mir weiter hilft. Dies soll mein bescheidener Beitrag zur Wissensweitergabe via Internet sein.

